Die Dokumentation ab Version 39.5.17 von PLANTA project finden Sie in der neuen PLANTA Online-Hilfe .
.
Performantes Customizing
Dieses Topic beinhaltet Erläuterung zu performanten und unperformanten Customizing.Python-API
Effiziente Nutzung von search_record()/get_children()
Informationen- Die Python API-Funktionen
ppms.search_recordsowieDtpRecord.get_childrenbesitzen einendi_list-Parameter. - Mit diesem Parameter werden die Dataitems, die von der API-Funktion geladen werden, eingeschränkt.
- Wird eine leere Liste übergeben, werden alle Dataitems aus der entsprechenden Datentabelle geladen, selbst wenn auf diese Attribute nicht zugegriffen wird.
- Dies führt zu einer erheblich längeren Laufzeit, um die entsprechenden Datensätze zu laden.
- Je mehr Dataitems in der Tabelle vorhanden sind, desto länger dauert es, jedes Attribut zu laden.
from ppms import ppms
project_record = ppms.search_record(461, ['000041'], []) # No restriction on the amount of dataitems to load
project_name = project_record.project_name.get_value()
total_remaining_effort = 0
for task_record in project_record.get_children(463): # No restriction on the amount of dataitems to load
remaining_effort = task_record.effort_rem.get_value()
total_remaining_effort += remaining_effort
ppms.ui_message_box(project_name, 'The remaining effort is {}'.format(total_remaining_effort))- Durch eine Einschränkung auf die relevanten Dataitems kann die Laufzeit des Makros verringert werden.
from ppms import ppms
project_record = ppms.search_record(461, ['000041'], ['project_name']) # The dataitems to load are restricted to "project_name"
project_name = project_record.project_name.get_value()
total_remaining_effort = 0
for task_record in project_record.get_children(463, ['effort_rem']): # The dataitems to load are restricted to "effort_rem"
remaining_effort = task_record.effort_rem.get_value()
total_remaining_effort += remaining_effort
ppms.ui_message_box(project_name, 'The remaining effort is {}'.format(total_remaining_effort))Wertebereiche
Datenbankzugriffe in computeOutput()
Teilabfragen in Wertebereichen- Ein klassisches Beispiel für ein unperformantes Customizing sind Datenbankabfragen innerhalb eines
computeOutput()-Wertebereichs. - Der PLANTA-Server geht beim Laden eines Moduls wie folgt vor (vereinfacht):
- Das Modul-Customizing wird analysiert, um festzustellen, welche Daten geladen werden müssen.
- Die Daten werden, eingeschränkt auf die Filterkriterien, aus der Datenbank geholt.
- Die Wertebereiche werden berechnet.
- Befindet sich ein
computeOutput()-Wertebereich auf einem der DIs im Modul, so muss dieser berechnet werden. - Die Berechnung findet für jeden Datensatz dieser Tabelle im Datenbereich statt.
- Ein
ppms.search_record()setzt eine Datenbankabfrage vom Server ab. - Da dies für jeden Datensatz geschehen muss, gibt es für den Datenbereich statt einer Datenbankabfrage, nun n-Abfragen, welche die Laufzeit verringern.
- Viele computeOutput-Wertebereiche lassen sich einfach in computeSqlValueRanges umwandeln, was sich positiv auf die Laufzeit auswirken kann.
Korrekte Definition von Abhängigkeiten (Dependencies)
Kurzübersicht- Die Wertebereichsfunktionen
computeOutput(),processInput()undcheckInput()brauchen eine definierte Liste von Abhängigkeiten. - Die Abhängigkeiten werden bei der Ausführung des Wertebereichs mit in den DtpRecord des Dataitems gepackt.
- Im Fall von
computeOutput()findet die Berechnung jedesmal statt, wenn sich eine der Abhängigkeiten ändert.
- Ein
computeOutput()-Wertebereich mit Abhängigkeit "Stern" versucht, sich so oft wie möglich neu zu berechnen. - Solange ein Dataitem mit Abhängigkeit "Stern" geladen ist, führt jedes Speichern, Rücksetzen und Filtern zu einer Neuberechnung, unabhängig davon, ob das Dataitem in dem Modul vorhanden ist.
- Wenn kein Modul, indem das Dataitem vorkommt, mehr geöffnet ist, wird es nicht mehr neu berechnet.
- Die ständige Neuberechnung kann bei komplexen Wertebereichen zu erheblich schlechterer Laufzeit führen.
- Wenn ein Dataitem sich neu berechnen soll, es aber keine DI-Abhängigkeit gibt, die man eintragen könnte, kann sich mit einer kleinen Umgehungslösung beholfen werden:
- Man legt ein virtuelles Dataitem in der gleichen Tabelle als Ja/Nein-Feld an.
- Dieses Dataitem wird als Abhängigkeit in das eigentliche Dataitem mit Wertebereich eingetragen.
- Soll sich das Dataitem neu berechnen, so invertiert man einfach den Wert des virtuelles DIs (
di.set_value(not di.get_value())).
Customizing
Datenbereiche customizen
Hinweis- Um Laufzeitproblemen vorzubeugen, ist es zu empfehlen beim Customizen der Datenbereiche pro Datenberich immer die Datenfelder aus derselben Datentabelle zu verwenden.
Datenbankabfragen minimieren
Die Latenz zwischen Datenbank- und Applikations-Server ist ein sehr wichtiger Punkt bei der Betrachtung von Performance.- Für jede Datenbankabfrage ist ein Round-Trip zwischen dem Applikations- und Datenbank-Server notwendig:
- Der PLANTA-Server sendet eine Abfrage an die Datenbank.
- Die Datenbank antwortet mit dem Ergebnis.
- Bei sämtlichem Customizing soll man deshalb immer die Anzahl der Datenbankabfragen minimieren.
- zwei Systeme miteinander verglichen:
- System "Lokal": Datenbank und PLANTA-Server sind auf der gleichen Maschine installiert, zwischen den beiden herrscht weniger als 1 ms Latenz.
- System "Remote": Datenbank und PLANTA-Server sind auf verschiedenen Maschinen installiert, zwischen den beiden herrscht eine Latenz von ungefähr 6 ms.
- zwei verschiedene Python-Makros ausgeführt, um Daten aus der Datenbank zu holen und die Zeiten zu messen.
- 1 Abfrage pro Eingabewert: Es wird über eine Liste von Ressourcen iteriert und für jede Ressource eine Abfrage an die Datenbank gesendet.
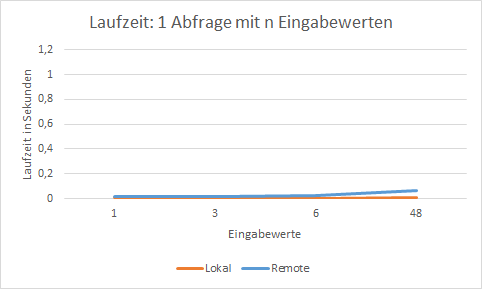
- 1 Abfrage mit n-Eingabewerten: Es wird eine Liste von Ressourcen als Parameter in eine Abfrage formatiert und an die Datenbank gesendet.
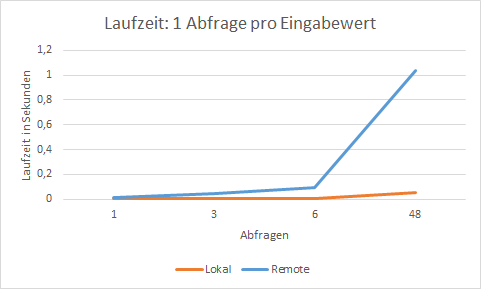
1 Abfrage pro Eingabewert
Folgendes Beispiel könnte "normaler" Code sein, den jemand ohne schlechtes Gewissen geschrieben hat
import time
from ppms import ppms
RESOURCES = ['R1', 'R8', 'R41']
def get_start_and_end_period_of_resource(resource_id):
"""Retrieve the start and end period of a resource"""
resource_record = ppms.search_record(467, [resource_id], ['start_period', 'end_period'])
start_period = resource_record.start_period.get_value()
end_period = resource_record.end_period.get_value()
return start_period, end_period
start = time.time()
for resource in RESOURCES:
start_period, end_period = get_start_and_end_period_of_resource(resource_id=resource)
end = time.time()
execution_time = round(end - start, ndigits=6)
ppms.ui_message_box('Executing the code took {} seconds!'.format(execution_time))- Für jede Ressource muss eine Datenbankabfrage (=
ppms.search_record) gesendet werden, welche im System mit höherer Latenz deutlich langsamer ist. - Wenn sich die Anzahl der abgefragten Ressourcen erhöht, steigt die Laufzeit mit jeder Ressource spürbar.
1 Abfrage mit n-Eingabewerten
Eine effizientere Version des vorherigen Codes:
import time
from ppms import ppms
RESOURCES = ['R1', 'R8', 'R41']
RAW_QUERY = """SELECT
DI001218 "resource",
DI001230 "start period",
DI001231 "end period"
FROM
DT467
WHERE
DI001218 IN ({resources})
"""
def get_start_and_end_period_of_resources(resources):
"""Retrieve the start and end period of a list of resources"""
formatted_resources = "'" + "', '".join(resources) + "'"
query = RAW_QUERY.format(resources=formatted_resources)
result = ppms.db_select(query)
periods = {}
for resource_id, start_period, end_period in result:
periods[resource_id] = start_period, end_period
return periods
start = time.time()
periods = get_start_and_end_period_of_resources(resources=RESOURCES)
end = time.time()
execution_time = round(end - start, ndigits=6)
ppms.ui_message_box('Executing the code took {} seconds!'.format(execution_time))- Nun werden sämtliche Start-/Endperioden mit Hilfe einer einzigen Datenbankabfrage geholt, egal wie viele Ressourcen abgefragt werden.
- Wenn sich die Anzahl der abgefragten Ressourcen erhöht, steigt die Laufzeit kaum.
Doppeltes Filtern
Oft wird in Modulen versehentlich doppelt gefiltert, was die Laufzeit unnötigerweise erhöht.- Oft wird dies durch unsaubere Modul-Makros verursacht.
- Wenn ein Modul initial aufgerufen wird, werden die Funktionen
on_load()undon_initial_focus()ausgeführt. - Wenn beide dieser Methoden ein
Module.menu(12)beinhalten, wird doppelt gefiltert.
Modul-Laden verzögern
Das Laden der Daten in einem Modul kostet stets Laufzeit, weswegen dies erst dann passieren sollte, wenn der Benutzer die Daten wirklich sehen will.- Ein Modul wird geladen, sobald es mit
Module.menu(12)gefiltert wird. - Um das Laden zu verzögern, muss das Filtern so spät wie möglich aufgerufen werden.
- Hierfür eignet sich die Modul-Methode
on_initial_focus(), da diese aufgerufen wird, wenn der Benutzer ein Modul zum ersten Mal fokussiert. - Ob das Laden der Modul-Daten noch aussteht, kann mit der Modul-Methode
Module.is_stub()überprüft werden.
on_initial_focus() Methode erst auf, wenn der Benutzer in das Modul klickt! - Hier muss im
on_load()gefiltert werden.
Filtern auf virtuellen Dataitems
Das Filtern auf virtuellen Dataitems ist immer langsamer, als das Filtern auf reelen Dataitems- Ein Filter auf einem reelen Dataitem wird von der PLANTA-Software direkt in die Datenbankabfrage eingefügt, um die Anzahl der Ergebnisse einzuschränken.
- Bei einem virtuellen Dataitem müssen zuerst alle Daten der Datentabelle aus der Datenbank geholt werden und diese dann innerhalb von PLANTA gefiltert werden.
- Ausnahme: Dataitems mit der Wertebereichsfunktion
computeSQLValueRangesowie Hol-Exits werden ebenfalls performant beim Laden der reelen Dataitems abgefragt
- Ausnahme: Dataitems mit der Wertebereichsfunktion
Verwendung von Caches
Wenn ein Wert sich kaum ändert, aber häufig gelesen wird, soll man sich überlegen, ob es nicht sinnvoll wäre, den Wert zu puffern.- Man muss sich dabei folgende Fragen stellen:
- Wie oft wird der Wert abgerufen?
- Ein Wert, der nur 1-2 mal pro Session abgerufen wird, ist kein guter Caching-Kandidat.
- Wie lange dauert es, den Wert zu ermitteln?
- Einfache Berechnungen, die bereits im Bruchteil einer Sekunde ermittelt werden, lohnen sich nicht, gecacht werden, hier kann der Aufwand, den Cache einzurichten und zu invalidieren, den Nutzen übersteigen.
- Wie häufig ändert sich der Wert?
- Werte, die ständig wechseln, sind keine guten Cache-Kandidaten, außer die Berechnung dauert länger und die Werte werden trotzdem an verschiedenen Stellen öfter benötigt.
- Wann muss ich den Cache leeren?
- Oft wird der Cache geleert, wenn sich der Wert ändert. In manchen Fällen reicht es aber auch, an bestimmten Punkten im Code den Cache zurückzusetzen, wenn man weiß, dass nur der nachfolgende Code auf den Cache zugreift.
- Von wo muss ich den Cache leeren können?
- Wenn ich in einem Modul eine Funktion mit Cache anbiete, dann muss auch eine Funktion angeboten werden, um diesen Cache zu leeren.
- Wie oft wird der Wert abgerufen?
- Die Parameter der gecachten Funktion sowie der Rückgabewert sollen primitive Datentypen sein (Zahlen, Texte, ...), keine PLANTA-Datentypen (DtpRecord, DataItem, ...).
- Wenn I-Texte Session-übergreifend gecacht werden sollen, muss die Sprache des Benutzers Teil der Parameter sein, sonst wird der I-Text in der Sprache des ersten Benutzers, der die Funktion aufruft, gecacht.
import functools from ppms import ppms @functools.lru_cache(maxsize=None) def get_dataitem_attributes(di_id): """Return the attributes of a DI or None if the DI is not valid""" di_record = ppms.search_record(412, [di_id], ['column_type', 'df_length', 'dt', 'di_name', 'format_id']) if di_record is None: return None column_type = di_record.column_type.get_value() df_length = di_record.df_length.get_value() dt = di_record.dt.get_value() di_name = di_record.di_name.get_value() format_id = di_record.format_id.get_value() return column_type, df_length, dt, di_name, format_id def cache_clear(): """Clear all caches used in this module""" get_dataitem_attributes.cache_clear()
Datenbank
Verwendung von Indizes
Information- Wenn Abfragen oft über dieselben Suchkriterien gefiltert werden, kann eine Performance-Verbesserung erreicht werden, indem man auf die Suchkriterien Indizes setzt.
- Die jeweilige Art des Index ist hierbei datenbankabhängig.


| I | Attachment | History | Size | Date | Comment |
|---|---|---|---|---|---|
| |
laufzeit_mehrere_abfragen.png | r1 | 8.2 K | 2016-06-30 - 01:00 | |
| |
laufzeit_n_eingabewerte.png | r1 | 6.3 K | 2016-06-30 - 01:00 |
{kind=link}
{kind=link}
|