Die Dokumentation ab Version 39.5.17 von PLANTA project finden Sie in der neuen PLANTA Online-Hilfe .
.
Übersicht über technische Neuerungen
Informationen- Im Folgenden ist ein Überblick über die wichtigsten Änderungen, die in Version S 39.5.0 des PLANTA-Servers eingeflossen sind, gegeben.
- Für diejenigen, die für den Betrieb des PLANTA-Servers verantwortlich sind, sind vor allem Architekturänderungen, das neue Installationsverfahren und der PLANTA-Dienst wichtig, da sich daraus Änderungen in der Umgebung, der Konfiguration und dem Betrieb ergeben können.
- Anwendungsentwickler, die auf Basis der PLANTA-Software individuelle Lösungen entwickeln und den Aufbau der bisherigen Releases kennen, sollen durch dieses Dokument ein Verständnis für neue Möglichkeiten und notwendige Anpassungen an Arbeitsweise und Customizings erhalten.
Release-Verfahren
Eine Aufspaltung des bisherigen Software-Komplettpaketes ermöglicht, die Entwicklung in einer Komponente unabhängig und terminlich entkoppelt von den anderen zu gestalten. Durch die Release-Planung für eine Komponente (statt für alle Komponenten zugleich) können sowohl schnellere Release-Zyklen eingehalten werden als auch eine fokussiertere Planung stattfinden. Dabei wird, soweit möglich, die Kompatibilität zu älteren Komponentenversionen gewahrt. So können auch Teilkomponenten aktualisiert werden, womit das bislang bestehende Risiko, unerwünschte Änderungen zusätzlich zu erwünschten zu erhalten, minimiert wird. Dieses Verfahren wurde für alle Client-Versionen ab C 39.5.0 eingesetzt sowie für den hier beschriebenen Server S 39.5.0. Dieser kann mit der Datenbank-Version 39.4.4.0 und dem Client C 39.5.2 eingesetzt werden.Architektur
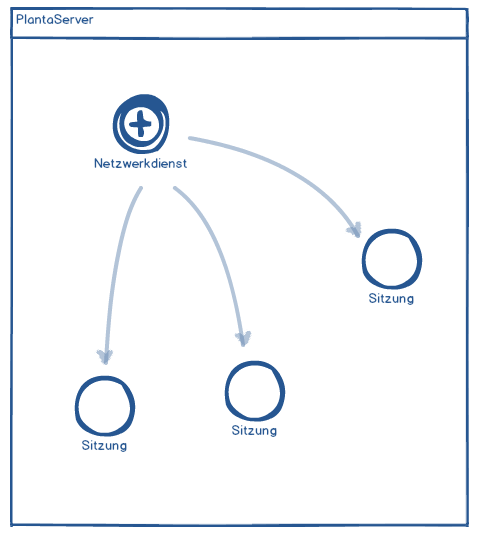
Im Zuge der Weiterentwicklung des PLANTA-Servers sind verschiedene Probleme sichtbar geworden, die auf der bis dahin verwendeten technischen Basis nicht vollumfänglich lösbar waren. Daher entstand mit einem neuen Architekturkonzept die Grundlage für künftige Entwicklungen, die auch unmittelbar Vorteile für Nutzer des PLANTA-Servers bietet. Bisherige Releases hatten durch die Nutzung einer 32bit-Architektur oft Schwierigkeiten mit großen Datenmengen und umfangreichen Berechnungen. In 32bit-Architekturen stehen Prozessen - je nach Betriebssystem und Konfiguration - nur 2-3 GB an adressierbarem Speicher zur Verfügung, was dazu führen konnte, dass das Betriebssystem trotz insgesamt genügendem Speicher keine Reservierung mehr zuließ. Dadurch konnte der Prozess nicht mehr weiterlaufen. Durch den Umstieg auf die 64bit-Architektur sind theoretisch 16 EiB adressierbar. Somit ist in der Praxis nur der insgesamt zur Verfügung stehende physische Speicher bzw. eine konfigurierte Speicherbegrenzung ein limitierender Faktor. In der bisherigen Architektur des PLANTA-Servers wurde für jede Client-Verbindung ein neuer Server-Prozess gestartet. Verwaltet wurde der Serverstart von einer eigenständigen Komponente namens ppmsd und Funktionalität des Betriebssystemes wie xinetd in Linux und Services in Windows. Jeder Prozess unterhielt eine eigene Datenbankverbindung über Client-Bibliotheken wie OCI und ODBC. In der neuen Java-basierten, multithreaded Architektur wird jede Session (≙ Client-Verbindung), die zuvor in einem isolierten Prozess ablief, im Kontext eines Threads verarbeitet. Daher entsteht bei einer Client-Verbindung kein neuer Prozess mehr; einzig der in der JVM laufende PLANTA-Server-Prozess ist so von außen sichtbar. Daher gibt es nun keinen zusätzlichen Dienst mehr, der bei einer Client-Verbindung den Server startet; stattdessen ist der PLANTA-Server gleichbedeutend mit diesem Dienst ("PLANTA-Service"). Zusätzlich haben wir eine Datenbankschicht realisiert, über die zur besseren Ressourcenauslastung Verbindungen geteilt werden.
In der neuen Java-basierten, multithreaded Architektur wird jede Session (≙ Client-Verbindung), die zuvor in einem isolierten Prozess ablief, im Kontext eines Threads verarbeitet. Daher entsteht bei einer Client-Verbindung kein neuer Prozess mehr; einzig der in der JVM laufende PLANTA-Server-Prozess ist so von außen sichtbar. Daher gibt es nun keinen zusätzlichen Dienst mehr, der bei einer Client-Verbindung den Server startet; stattdessen ist der PLANTA-Server gleichbedeutend mit diesem Dienst ("PLANTA-Service"). Zusätzlich haben wir eine Datenbankschicht realisiert, über die zur besseren Ressourcenauslastung Verbindungen geteilt werden.
 Bedingt durch den Einsatz von Java und eine stärkere Aufteilung in Komponenten hat sich auch die Ordnerstruktur deutlich verändert. Wie bisher existiert das Verzeichnis
Bedingt durch den Einsatz von Java und eine stärkere Aufteilung in Komponenten hat sich auch die Ordnerstruktur deutlich verändert. Wie bisher existiert das Verzeichnis py, in dem das Python-Customizing abgelegt ist. Die interne Struktur dieses Verzeichnis wurde jedoch neu angeordnet. Mehr Informationen dazu finden Sie hier. Außerdem ist für die Konfiguration des PLANTA-Servers das Verzeichnis conf wichtig, da hier - thematisch in mehrere Dateien aufgeteilt - Einstellungen vorgenommen werden können. Näheres dazu finden Sie hier.
Datenbank
Durch die Datenbank-Abstraktionsschicht ist PLANTA dem Ziel einer Datenbankunabhängigkeit näher gekommen und kann dadurch bereits für die PLANTA-interne Entwicklung Customizing-Daten versionieren. Es wurden weiterhin umfangreiche, teilweise optional einsetzbare Mechanismen zur sicheren Identifikation von Datensätzen, zum Schutz von Daten gegen Korruptionen und gegen Customizing-Fehler entwickelt.Die Verwendung einer Datenbankabstraktionsschicht namens Hibernate ermöglicht Folgendes:
- Gemeinsame Verwendung von Verbindungen (Connection Pooling)
- Erkennung von Verbindungsproblemen mit der Datenbank
- Einsatz eines einheitlichen Datenbank-Clients (JDBC)
Ein bereits genutzter Vorteil aus dem Einsatz von Hibernate ist die Historisierung der Customizing-Tabellen. Für jede Tabelle der Schemas Q1B und Q2B existiert eine weitere Tabelle, in der jede Änderung aufgezeichnet wird. Vorherige Customizing-Stände kann man so wiederherstellen bzw. Änderungen nachvollziehen. Zunächst ist dieses Feature nur für PLANTA zugänglich.
Da für jede dieser Tabellen eine Klasse im PLANTA-Server existiert, können, außer in der DT400, keine Schemaveränderungen (DI hinzufügen oder löschen) mehr durchgeführt werden. Auch kann man Tabellen der Schemas Q1B und Q2B nicht mehr löschen oder hinzufügen. Änderungen dieser Art waren zuvor bereits nur PLANTA vorbehalten. UUIDs (Universally Unique Identifier) dienen als Schlüsselfelder der Identifizierung von Datensätzen. Dadurch können auch Schlüsseländerungen, wie sie beim Drag&Drop notwendig sind, durchgeführt werden. Beispielsweise kann man daher im Modul Arbeitsgebiete Module von einem Arbeitsgebiet in ein anderes verschieben, was vorher nicht unterstützt wurde. Aktuell gibt es die UUIDs nur in der Q1B sowie Q2B. Daher ist Drag&Drop-Verschieben mit Schlüsseländerung nur in den Datentabellen dieser beiden Schemas möglich. Optional können auch weitere (individuelle) Tabellen mit UUIDs ausgestattet werden und dadurch die genannten Vorteile nutzen.
Bereits während des Starts des Servers wird eine Customizing-Validierung durchgeführt, die Datengerüste (DIs, DTs und Relationen) auf korrektes Customizing prüft. Gefundene Fehler werden einem Benutzer mit Customizing-Rechten in einer Dialogmeldung bei der Anmeldung präsentiert. Dadurch erhält der Anwendungsentwickler die Möglichkeit, Customizing-Fehler nicht erst nach Auftreten von Fehlerzuständen durch Analyse, Nutzerbeschwerden oder Log-Nachrichten zu bemerken und zu berichtigen, sondern bereits im Vorfeld.
Python
Durch ein Python-Update sind einige in Python enthaltene Fehler und Performance-Probleme behoben worden. Eine neue Verzeichnisstruktur für Python-Customizing soll Anpassungen und Updates erleichtern. Die bisher eingesetzte Python-Version 3.0 ist auf Version 3.2 angehoben worden. Details zu Verbesserungen können auf der Python-Websitepy des Server-Verzeichnisses nun die neuen Verzeichnisse system, planta_de, planta_ch und customer. Die Struktur in diesen Verzeichnissen ist identisch. system enthält eine Übermenge aller Dateien, die in den übrigen Verzeichnissen vorhanden sind. Allerdings sind diese Dateien (wie auch die Ordnerstruktur) generiert. Sie dienen beim Einbinden eines Python-Moduls über import als Wrapper, was Überschreiben von Funktionalität ermöglicht. Wenn neue Python-Quelldateien oder Pakete hinzugefügt werden sollen (also nicht nur überschrieben), muss eine Neugenerierung der Python-Struktur angestoßen werden. Weitere Informationen dazu finden Sie hier.
Durch die Architekturänderungen läuft nun, im Gegensatz zu vorher, nur noch ein Python-Interpreter für alle Instanzen. Dadurch ergeben sich architekturelle Einschränkungen bezüglich des Python-Customizings.
So muss von der Nutzung von Session-Daten über __builtins__, Module und Klassenvariablen abgeraten werden, da diese Speicherorte nun für alle Sessions zur Verfügung stehen. Beispielsweise kann ein Modulobjekt, dass über __builtins__['my_module'] zugreifbar ist, über __builtins__['my_module'].menu(49) aus jeder Session geschlossen werden.
Um weiterhin über eine Session hinweg eine Speicherungsmöglichkeit zu erhalten, existiert die Funktion
get_session_dict(), die ein Dictionary zurückliefert, welches statt der __builtins__ oder anderer globaler Speichermöglichkeiten verwendet werden sollte.
Installation, Migration und Betrieb
Ein neues Installationsverfahren vereinfacht die Einrichtung des PLANTA-Servers deutlich. Dieses erlaubt die Einrichtung sowohl über eine graphische Oberfläche als auch über die Konsole. Da der Installer auf Java basiert, ist die Einrichtung auf verschiedenen Plattformen weitgehend einheitlich. Das Topic Aktualisierung von Client und Server mit dem automatischen Installer beschreibt Verwendung und Voraussetzungen zur Installation. Außerdem kommen nun - statt der vorher üblichen Update-Skripte beim Einspielen eines Hotfixes - Migrationspakete zum Einsatz. Migrationspakete können und sollen auch für individuelle Anwendungsentwicklungen verwendet werden. Für die Installation des PLANTA-Servers als Hotfix auf einer bestehenden PLANTA 39.4.4.0-Installation existieren Skripte, die für den Einsatz von Release S 39.5.0 benötigt werden. Diese rüsten auch die Infrastruktur für den Einsatz von Migrationspaketen nach. Eine detaillierte Beschreibung der benötigten Migrationsschritte finden Sie hier. Auch die Einrichtung des plattformunabhängigen PLANTA-Diensts übernimmt der Installer. Über diesen kann der Server einheitlich gestartet, neu geladen und gestoppt werden.Authentifizierung
Die Authentifizierung kann nun neben den bekannten Authentifizierungsmechanismen ein Kerberos-Dienst übernehmen. Hierdurch ist in PLANTA project auch Single-Sign-On möglich. Eine Anbindung beispielsweise an Active Directory von Microsoft ist durch die Kerberos-Authentifizierung durchführbar. Die Konfiguration von PLANTA-Server und PLANTA-Client ist hier beschrieben.| Siehe auch: Release Notes |


| I | Attachment | History | Size | Date | Comment |
|---|---|---|---|---|---|
| |
MultiProzessArchitektur.png | r2 r1 | 28.0 K | 2021-01-21 - 15:56 | |
| |
MultiThreadedArchitektur.png | r2 r1 | 16.5 K | 2021-01-21 - 15:56 |
{kind=link}
{kind=link}
|