Customizing-FAQ
Allgemeines
Was ist Python?
Python ist eine Programmiersprache, die mehrere Programmierparadigmen ermöglicht. So werden
objektorientierte
,
aspektorientierte und
funktionale Programmierung unterstützt.
Warum Python?
Python hat eine wunderbar einfache Syntax und lässt sich extrem gut in C integrieren.
Wo finde ich die Beschreibung der Python-Funktionen, die PLANTA bereitstellt?
Die Funktionen werden in der
Python-API beschrieben.
Was ist der DTP?
DTP bedeutet Data Table Pool. Die PLANTA-Software legt dort alle aus der Datenbank geladenen (z.B. per Modul-Suche oder mit den Python-Funktionen:
search_record,
get_children etc.) Datensätze ab. Die Datensätze werden dann dort zur Darstellung in einem oder mehreren Modulen vorgehalten.
Was ist ein MTS Record?
MTS bedeutet Module Tree Structure.
- MTS Records sind Moduldatensätze, d.h., die Datensätze, die im Modul angezeigt werden.
- Zu jedem MTS Record gehört genau ein DTP Record.
- Beispiel: Ein Projekt mit all seinen Feldern
Wie wird die I-Nummer für einen I-Text generiert?
PLANTA generiert anhand des Eintrages in der schemaspezifischen Zählerstandtabelle eine neue I-Nummer für einen I-Text.
Abhängig von der Lizenz und des I-Nr. DIs, wird der Wert des Zählerstand 1 DIs ausgelesen und für einen neuen I-Text genommen.
- Beispiel für Q2B
- Zählerstandtabelle: DT 396 Zählerstand Q2B
Lizenzdataitem: DI 008150 Lizenz = Kundenlizenz
DI-Dataitem: DI 008152 DI = 000985 (I-Nr. DI aus der DT434 I-Nr. Q2B)
Zählerstanddataitem: DI 008164 Zählerstand 1
Hat sich etwas bei den I-Texten im Vergleich zu Releases < 39 geändert?
I-Texte werden in PLANTA
project nur noch in der schemaspezifischen I-Text-Tabelle abgelegt.
Die I-Nummern-Tabelle wird nicht mehr gepflegt und befüllt.
Warum wird keine automatische Nummer erzeugt?
Die automatische Nummer wird erst erzeugt, wenn alle DIs des Fremdschlüssels des Datensatzes mit gültigen Werten und, falls vorhanden, alle Muss-Felder gefüllt sind.
Hinweis
- Ein Strich-Datensatz ist nur dann ein gültiger Wert, wenn im Modul PLANTA Datentabelle in der dazugehörigen Datentabelle das DI004269 Strich-DS anlegen aktiviert ist.
Einstellungen
Wie richte ich die PLANTA-E-Mail-Funktion (um E-Mails direkt zu versenden) ein?
Im Modul
Globale Einstellungen muss die richtige IP-Adresse des smtp-Servers beim Parameter
smtp_server_adress im Feld
Alpha (120) eingetragen werden.
Weitere Informationen
Wie kann man den Systemtitel ändern?

Der Systemtitel (im Titelbalken/Titelleiste) wird im Modul
Lizenz, Systemparameter und DB-Instanzen im Feld
Systembezeichnung hinterlegt und kann dort geändert werden.
Hinweis
- Alternativ kann auch zur Laufzeit der Systemtitel mit der folgenden Python-Funktion geändert werden:
ui_set_system_title(title: string)
Tipp
- Zur Auseinanderhaltung von verschiedenen Sessions können z.B. der aktuell angemeldete Benutzer und die PID im Systemtitel angezeigt werden.
- Wird das Standard-Benutzermenü MOD0099QC verwendet:
- Das Modul Pythonmakros öffnen und in der on_load-Methode die Variable
CHANGE_TITLE von CHANGE_TITLE=FALSE auf CHANGE_TITLE=TRUE ändern.
- Wird ein individuelles Benutzermenü verwendet:
- Das Modul Pythonmakros öffnen und in der on_load-Methode des Benutzermenüs folgende Zeilen einfügen:
- Die folgenden Zeilen müssen, wie auch die anderen Zeilen in der on_load-Methode, mit jeweils vier Leerzeichen eingerückt werden.
PID = str(os.getpid())
ppms.ui_set_system_title('Systemtitel' + ', PID: ' + PID + " - " + ppms.uvar_get("@1"))
Details
- Ab dem nächsten Start von PLANTA project wird die PID im Systemtitel angezeigt.
- Die PID ist auch Bestandteil des Logfiles, sodass ein Logfile immer der entsprechenden Session zugeordnet werden kann.
Wie kann man den Editor ändern, der aufgerufen wird?
In mehreren Modulen kann über einen Button ein Editor aufgerufen werden, z.B. im Modul
Module über den Button
Python-Makrobearbeitung aufrufen. Welcher Editor dabei verwendet wird, wird in der globalen Einstellung
py_editor (im Modul
Globale Einstellungen) hinterlegt. Wird dort ein falscher Pfad angegeben, kommt die Meldung
„Error executing python script: Das System kann die angegebene Datei nicht finden“.
Wie kann ich ein eigenes Produktlogo (Firmenlogo) hinterlegen bzw. systemweit einsetzen?
- Um pro Modul ein individuelles Produktlogo zu hinterlegen:
- Um das Logo in der Kopfzeile (Druckkopf) in den Standarddruckbereichen auszutauschen:
- Den Datenbereich mit Positionierung = 3 ( Druckbereich: Kopfzeile) des Moduls, das im Skin des angemeldeten Benutzers im Datenfeld Modul für Druckber. hinterlegt ist aufrufen.
- Dort die Identnummer des OLE-Objekts mit der des neu angelegten OLE-Objekts ersetzen.
- Das Logo in individuellen Druckbereichen muss ggf. genauso ausgetauscht werden.
- Um das eigene Produktlogo systemweit einzusetzen:
- Ein neues OLE-Objekt für das Produktlogo anlegen und der Kategorie Produktlogos zuordnen.
- In die Modulvariante Produktlogos wechseln.
- Bei dem neu angelegten OLE-Objekt die Schaltfläche Systemweit als Logo verwenden betätigen.
Fragen zum Verhalten ("Warum?")
Warum wird ein neu gecustomiztes Kontextmenü nicht angezeigt?
- Das Feld muss in einem der sichtbaren Fenster (Fenster 1-3) gecustomized werden.
In welchem Verhältnis stehen die Grössen: Feldbreite, Einrückung und Breite Fenster 1, 2 und 3 zueinander?
- Die Werte für DF-Breite und Einrücken werden in der gleichen Einheit, in Zehntelmillimetern angegeben.
- Die Angabe in Breite F1 etc. ist keine Größenangabe, sondern dient lediglich zur Berechnung des Anteils des Fensters an der gesamten Bildschirmbreite.
- Da die Breite von Bildschirmen (und damit die dem Panel „zur Verfügung stehende Breite“) unterschiedlich ist, ist dies kein fest definierter Wert.
Was sind implizite Hol-Exits?
In PLANTA
project gibt es mit impliziten Hol-Exits eine Alternative zu Hol-Exits, die Dataitems aus übergeordneten Datentabellen anzeigen.
Details
- Um Daten aus übergeordneten Datentabellen anzuzeigen, muss kein Exit gecustomized werden, es kann einfach das Dataitem selbst in den Datenbereich mit aufgenommen werden.
Achtung
- In Modulen mit großen Datenmengen sollten implizite Hol-Exits aus Performancegründen nicht verwendet werden.
- Weitere Informationen zu Performanceverbesserneden Massnahmen sehen Sie hier.
Warum werden Felder in einem neuen Fenster nicht angezeigt?
Soll ein Feld im Fenster 2 (bzw. Fenster 3) angezeigt werden, muss zusätzlich im Modul
Weitere Modulparameter ein Wert im Datenfeld
Breite F2 (bzw.
Breite F3) eingetragen werden.
- Beim Anlegen eines neuen Moduls im Modul Module wird über einen Standardwert in Breite F1 eine Breite für das Fenster 1 festgelegt, daher muss hier nicht explizit eine vergeben werden.
Hinweis
Woran liegt es, dass eingetragene und gespeicherte Werte unter der Skala nach einem Neustart verschwunden sind?
- Bei Modulen, bei denen eine Eingabe in eine Projektion möglich sein soll, muss geprüft werden, ob im Datenbereich, der die Projektions-Dataitems enthält, der Parameter Ausgabe deaktiviert ist. Wenn nicht, kann der Wert nicht gespeichert werden (er wird angezeigt, aber nach Neustart sieht man, dass er nicht gespeichert wurde).
Warum kann man ein neu angelegtes DI nicht verwenden/Warum wirken Änderungen am DI nicht?
Wurde PLANTA mit
Forking-Server installiert, muss nach jeder Änderung an Dataitems der Forking-Server neugestartet werden. Im
Data Dictionary und im
Dataitems gibt es dafür den Button
Reload Forking-Server.
Hinweise
- Bei Änderungen an folgenden Datentabellen muss der Forking-Server neu gestartet werden:
- Ausnahme ist eine Änderung an
- I-Texten z.B. der DI-Bezeichnung oder
- Wertebereichen (auch der WB-Art)
Wie wird die Höhe und Breite von Listboxen eingestellt?
- Die Höhe (bzw. Breite) von Listboxen muss nicht manuell eingestellt werden, sondern sie wird anhand der Anzahl der Werte (bzw. Breite der Felder) berechnet.
- Es gibt eine minimale und eine maximale Höhe bzw. Breite.
Wie sind die Währungsformate standardmäßig gecustomized?
Im Standard werden systemweit Währungsformate mit zwei Stellen nach dem Komma verwendet. Wenn man dieses Format für einzelne Module bzw. Datenfelder anpassen möchte, kann das auf Datenfeld-Ebene individuell geändert werden (Feld
Format-ID ).
Warum kann aus einer Listbox kein Wert ausgewählt werden?
Bei dem Wert, der aus der Listbox übernommen werden soll, muss im Listboxmodul der Parameter
LB: Wertübernahme aktiviert sein.
Tipp
Warum kann ich, obwohl der Customizing-Modus aktiviert ist, keine Felder anklicken?
Es gibt zwei mögliche Ursachen:
- Der Datenbereich, in dem die Felder sind,
- wurde noch nicht durch Reinklicken aktiviert (der Datenbereich wird noch grün angezeigt) oder
- ist keine Maske (Layout = 0 oder 1). Der Datenbereich wird grau angezeigt.
- Tipp: Durch Rechte Maustaste in einem Bereich und Auswahl des entsprechenden Eintrags kann das Layout geändert werden.
Kann ich im Customizing-Modus mehrere Felder auf einmal aktivieren?
Für das Markieren von mehreren Elementen gibt es gibt zwei Möglichkeiten:
-
- Die gewünschten Elemente einzeln nacheinander mit STRG + Linke Maustaste anklicken.
- Mehrere Elemente in einem Bereich markieren.
- Durch Gedrückthalten der SHIFT-Taste, der linken Maustaste und Bewegen der Maus wird um den entsprechenden Bereich ein Rahmen gezogen.
- Beim Loslassen der linken Maustaste werden alle Elemente, die vollständig im Bereich des Rahmens liegen, markiert.
- Um weitere Elemente auf die gleiche Weise zu den bereits markierten Elementen hinzuzufügen, zusätzlich STRG gedrückt halten.
Warum werden alternierende Schattierungen schwarz angezeigt?
Im entsprechenden Datenbereich ist das DI
Farbintensität F1 (
Farbintensität F2 bzw.
Farbintensität F3) zwar gefüllt, das dazugehörige DI
Altern. Farbe F1 (
Altern. Farbe F2 bzw.
Altern. Farbe F3) jedoch nicht. Ist dieses Feld leer, wird standardmäßig die Farbe Schwarz (in der angegebenen Intensität) für die alternierende Schattierung verwendet.
Warum wirkt ein Filterkriterium in rekursiven Strukturen nicht wie erwartet?
Über den Parameter
Filter anwenden auf kann eingestellt werden, auf welcher Ebene in der rekursiven Struktur die Filterkriterien wirken sollen, daher sollte dieser Parameter geprüft werden.
Warum wirkt ein Filterkriterium nicht?
Über den Parameter
Filter deaktiviert kann ein Filterkriterium deaktiviert werden.
Warum werden die Charts in einem kopierten Modul nicht angezeigt?
- Aus welchem Datenbereich die Daten für den Chart kommen, wird im Chart-Datenfeld im Feld Datenfeld-Konfiguration im Parameter
da_id='' definiert.
Beispiel
"""Define Chart - Properties"""
da_id='045968'
- Wird ein Modul kopiert, ändern sich die IDs der Datenbereiche. Daher muss in Chart-Datenfeldern die Datenbereichs-ID des Quell-Moduls durch die des neuen ersetzt werden.
Tipp
- Welche Datenbereichs-ID verwendet werden muss, findet man am einfachsten heraus, in dem man sich anschaut, welcher Datenbereich im Quell-Modul verwendet wurde und welcher diesem im kopierten Modul entspricht.
Customizing-Tipps ("Wie?")
Wie können Zeilenumbrüche in einem Datenfeld eingestellt werden?
Über den Parameter
Mehrzeilig können sowohl manuelle als auch automatische Zeilenumbrüche eingefügt bzw. angezeigt werden.
Wie wird der (im Standard blaue) Rahmen um eine Listbox gecustomized?
Die Farbe für den Rahmen um eine Listbox wird im Modul
Weitere Modulparameter im Parameter
Background-Symbol hinterlegt.
Hinweis
- Das Blau im Standard hat die Symbol-ID 001975.
Wie kann der Inhalt der aktuellen @L-Variablen (Listenvariablen) angezeigt werden?
Ein Anwender mit Customizer-Rechten kann durch Klick auf die Schaltfläche
Aktuelle @L-Werte anzeigen im Modul
Variablen die aktuellen @L-Werte einsehen.
Wie kann der Inhalt einer bestimmten Variablen angezeigt werden?
Ein Anwender mit Customizer-Rechten kann im Modul
Variablen durch Klick auf die Schaltfläche
Variableninhalt anzeigen und durch Eingabe der entsprechenden Variablen ihren Inhalt einsehen.
Wie kann die Ausrichtung des Datenfeldinhalts geändert werden?
Durch Setzen des Parameters
Ausrichtung auf Datenfeldebene.
Wie kann man die Performance beim Customizen der Ressourcenstruktur verbessern?
Wenn die Struktur nicht mit einem Datenbereich aus der DT469
Ressourcenstruktur gecustomized wird, sondern in dem Datenbereich der DT467 in dem Feld
Rekursive Relation eine entsprechende Relation gecustomized wird.
Wie kann man ein neu aufgerufenes Untermodul als Reiter hinter dem Hauptmodul customizen?
Der Parameter
dock_to_module in der Methode
open_module() muss gleich der UID des Moduls, an das das Untermodul angedockt werden soll gesetzt werden.
Beispiel
mod_obj = ppms.get_target_module()
mod_obj.open_module('ID des Moduls',forced_status=2,dock_to_module=mod_obj.get_uid(),dock_style=0,foreground=0,focus=0)
- Erklärung:
- mod_obj ist das Hauptmodul, an das Untermodul angedockt werden soll.
Wie kann ich einen Datensatz aus dem DTP auslesen bzw. aus der Datenbank in den Pool holen?
Dafür wird die Python-Methode
search_record(dt_num, key_list, di_list, dblookup) verwendet.
Parameter
- dt_num: ID der Datentabelle
- key_list: Liste der Python-IDs der 1:1-Schlüssel der Datentabelle
- Bei zusammengesetzten Schlüsseln müssen alle DIs (Reihenfolge wie in der Datentabelle) angegeben werden.
- di_list: Liste mit den DI-IDs (ohne führende Nullen) die im DTP enthalten sein sollen
- Hier müssen alle DIs angegeben werden, auf die in der weiteren Berechnung zugegriffen wird.
- dblookup: Gibt an, ob der Wert aus der Datenbank gelesen werden soll, falls der Datensatz im Pool nicht existiert.
Hinweise
- Die Liste di_list muss mindestens ein DI enthalten.
- 1:1-Schlüssel und Fremdschlüssel werden automatisch in den DTP geladen, auch wenn sie nicht in der Liste di_list enthalten sind.
Beispiele
pr_id = 4711
rec461=ppms.search_record(461, [pr_id], [1052,1062], True)
- Erklärung
- Die Variable rec461 enthält nun eine DTP-Datensatz mit den folgenden DIs (zusätzlich zu den Primär- und Fremdschlüsseln der DT461)
- 001052 Hauptprojekt-ID
- 001062 Manager
pr_id = 4711
task_id = 2010
res_id = R1
rec466=ppms.search_record(466, [pr_id,task_id,res_id], [1510], True)
- Erklärung
- Die Variable rec466 enthält nun eine DTP-Datensatz mit dem DI 001510 Belastung-Ist (zusätzlich zu den Primär- und Fremdschlüsseln der DT466).
Wie kann man zwei (oder mehr) Datenfelder hinter einem Balken anzeigen?
Um neben einem Balken zwei (oder mehr) sogenannte
Balkenhilfsfelder anzuzeigen,
- für beide Datenfelder im Parameter Balkenlink (DF-Python-ID) die Python-ID des Balken-Datenfelds eintragen
- im Parameter Andockpunkt die Position des Balkenhilfsfelds definieren z.B. 1 Startpunkt ist Balkenende
- X-Pos des 2. Datenfelds = X-Pos des 1. Datenfelds + DF-Breite des 1. Datenfelds + 1
Wie kann ich ein Datenfeld ohne Überschrift anzeigen lassen?
- Wenn der Datenbereich ein horizontales Layout (Parameter Layout = 0) oder ein vertikales Layout (Layout= 1) hat,
- im Modul Datenbereiche für das Datenfeld, dessen Überschrift nicht angezeigt werden soll, in den Parameter DF-Überschrift ein geschütztes Leerzeichen (Alt+ 0160) eintragen.
- Ist der Datenbereich eine Maske (Layout = 2), so kann man die Überschrift ausblenden
- indem man im Modul den Menüpunkt Customizing-Modus aktiviert, die Überschrift anklickt und auf ENTF drückt oder
- indem man die X/Y-Positionen der Überschrift in der Modulvariante Layout im Modul Datenbereiche entfernt.
Was kann ich tun, um die Performance zu verbessern?
- Sind die meisten Module langsam,
- Ist ein spezielles Modul langsam,
- Filterkriterien überprüfen (Filtern von, Filtern bis, Regulärer Ausdruck)
- Sind auch Filterkriterien auf reellen und nicht nur auf virtuellen Datenfeldern (Dataitems)?
- Grund: Filterkriterien auf reellen Dataitems werden in der Datenbank ausgewertet, die auf virtuellen im Hauptspeicher – d.h. wenn in einem Modul nur Filterkriterien auf virtuellen Dataitems gesetzt sind, werden erst alle Daten in den Hauptspeicher geladen, um dann dort auf die Filterkriterien einzuschränken.
- Das gleiche gilt für reguläre Ausdrücke.
- Die meisten Wertebereiche und Hol-Exits können in einen Python-Wertebereich mit der Funktion computeSqlValueRange() umgewandelt werden. Felder mit solchen Wertebereichen sind der Datenbank bekannt. Daher wirken Filterkriterien auf diesen Feldern nicht erst im Hauptspeicher, sondern auf der Datenbank.
- Implizite Hol-Exits sollten aus Performancegründen nicht in Modulen mit großen Datenmengen verwendet werden.
- Ist das Laden eines Panels langsam oder stockt das Laden der Reiter bei bestimmten Untermodulen,
- Ist eine bestimmte gecustomizte Funktion langsam,
Customizen in zwei Sessions
Ist der Parameter
DTP Cache im Modul
PLANTA Datentabelle für die Datentabellen DT404, DT405, DT406, DT410, DT411 und DT412 aktiviert, sieht man Customizing-Änderung nur in der aktuellen Session und in allen danach gestarteten, aber nicht in allen, die bereits offen sind. Der Vorteil dieser Einstellung ist eine bessere Performance ab dem zweiten Aufruf. Ist der Parameter deaktiviert, sieht man eine Änderung auch in allen bereits offenen Sessions nach Neustart des Moduls, allerdings dauert jeder nachfolgende Modulaufruf gleich lang wie der erste.
Begründung: Ist der Parameter aktiviert, werden die Daten aus den entsprechenden Datentabellen beim ersten Laden in den
DTP Cache geladen und bei jedem weiteren Zugriff werden die Daten nicht aus der Datenbank, sondern aus dem
DTP Cache verwendet.
Strg + F3 zum Öffnen des aktuellen Datenbereichs / F9 zum Öffnen des Moduls
Benutzer, denen die Customizer-Menüpunkte zugeordnet sind, können
- mit F9 das Customizing des aktuellen Moduls im Modul Module aufrufen
- mit STRG + F3 den Datenbereich, in dem sich der Fokus befindet, im Modul Datenbereiche aufrufen.
Automatisches Anlegen von Inkarnationen
Im
Data Dictionary gibt es die Möglichkeit
Inkarnationen automatisch anzulegen.
Round-Wertebereiche aus Performancegründen in Compute SQL-Wertebereiche umwandeln
Ein Round Wertebereich wie z.B. der von DI003394 kann unter Umständen performancekritisch sein. Wir empfehlen daher diesen in einen Compute SQL Wertebereich umzuwandeln.
Beispiel alt
(ROUND(DI001510,2) != 0.00) ||
(ROUND(DI002669,2) != 0.00) ||
(ROUND(DI002671,2) != 0.00)
Beispiel neu
def computeSqlValueRange(dt_name):
val = """case
when nvl(DI001510,0)+nvl(DI002669,0)+nvl(DI002671,0) > 0 then 1
when nvl(DI001510,0)+nvl(DI002669,0)+nvl(DI002671,0) = 0 then 0
end"""
return str(val)
Python: Wie füge ich Elemente zu einer Liste hinzu?
value_list = [["R1"],["R2"],["R3"]]
f_list = []
i = 0
for rec in value_list:
f_list.append(value_list[i][0])
i = i + 1
- Variante 1 (Strukturiert)
value_list = [["R1"],["R2"],["R3"]]
f_list = []
for rec in value_list:
f_list.append(value_list[0])
value_list = [["R1"],["R2"],["R3"]]
f_list = [rec[0] for rec in value_list]
Technische FAQ
Warum können Dateien größer 400KB unter MSSQL nicht gespeichert werden?
Erscheint beim Versuch, eine Datei größer 400KB unter MSSQL zu öffnen die Fehlermeldung
Connection is busy with results for another hstmt, wird ein alter ODBC SQL Server Driver verwendet.
- Die aktuelle Version finden Sie hier unter Microsoft® SQL Server® 2012 Native Client
Was bedeuten die Meldungen ... no version information available (required by ./planta_server) beim Starten von PLANTA project?
Wenn sie beim Starten von PLANTA folgende bzw. ähnliche Meldungen bekommen, deutet es darauf hin, dass Sie die von PLANTA gelieferten SAP libs verwenden. Für den Fall, dass die SAP-RFC-Schnittstelle nicht genutzt wird, sind im aktuellen Server-Paket funktionslose Ersatzbibliotheken enthalten, die ggf. installierte Originalbibliotheken maskieren. Sollten Sie keine RFC-Schnittstelle (BAPI) verwenden, ist diese Meldung daher nicht relevant.
./planta_server: ./libsapucum.so: no version information available (required by ./planta_server)
./planta_server: ./libsapnwrfc.so: no version information available (required by ./planta_server)
Beim Verwenden der RFC-Funktionalität (BAPI) lesen Sie bitte die folgenden Hinweise:
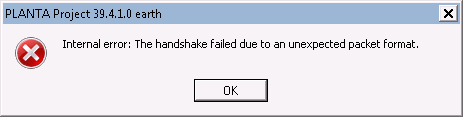
Beim Starten erscheint die Fehlermeldung Internal error: The handshake failed due to an unexpected packet format. Was bedeutet das?
Erscheint beim Starten des Clients folgende Fehlermeldung, ist der Client verschlüsselt eingestellt (Parameter
encrypted = yes), der Server jedoch nicht.
Beispiel
Beim Starten des Dienstes bzw. Programms erscheint die Fehlermeldung Der Dienst "XXX" auf "YYY" konnte nicht gestartet werden. ...
Auf Windows-Servern wird eine aktualisierte Version der
Microsoft Visual C++ 2005 SP1 Laufzeitumgebung in der x86-Variante benötigt. Ist diese nicht vorhanden, erscheint die folgende Fehlermeldung:

Woran erkennt man, welche/s Release/Version verwendet wird?
- Prüfen der Server-, Client- und Datenbank-Version. Hierzu
- den Client starten und anmelden
- STRG + B drücken: Das Modul Systeminformation öffnet sich.
- In den Feldern Client, Server und Customizing stehen die 5-stelligen Changeset-Nummern.
- Zu welcher Version diese Changesets gehören finden Sie hier...
- Im Feld Customizing wird zusätzlich zu der Changeset-Nummer bereits die aktuelle Version angegeben.
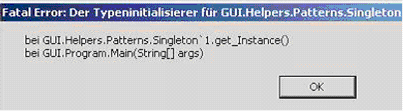
Beim Starten erscheint die Fehlermeldung Fatal Error: Der Typeninitialisierer... Was bedeutet das?
Erscheint beim Starten des Clients die abgebildete Fehlermeldung, ist .Net 3.5 nicht installiert. Das ist eine Voraussetzung für PLANTA
project.
Weitere Voraussetzungen
Beispiel
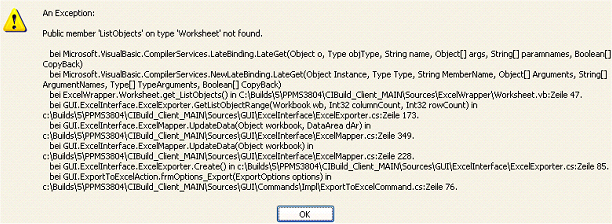
Beim Versuch nach Excel zu exportieren, kommt die Fehlermeldung Public member ‘ListObjects’ on type ‘Worksheet’ not found. Woran liegt das?
Kommt beim Versuch, ein Modul nach Excel zu exportieren, die abgebildete Fehlermeldung, wird die installierte Office-Version nicht unterstützt. Eine Voraussetzung für den Export nach Excel ist Microsoft Office > 2003.
Weitere Voraussetzungen für PLANTA project
Beispiel


{kind=link}