Die Dokumentation ab Version 39.5.17 von PLANTA project finden Sie in der neuen PLANTA Online-Hilfe .
.
FAQ
Allgemeine Funktionen
- Allgemeine FAQ
- Wie finde ich am schnellsten die benötigten Informationen in der Dokumentation?
- Wie finde ich die Beschreibung eines bestimmten Moduls?
- Wo finde ich die ID eines Moduls?
- Ein Modul, das ich oft benutze, enthält viele Felder, die ich nicht brauche. Kann ich diese dauerhaft ausblenden?
- Wie kann man die Zeitskala zoomen?
- Wie strukturiere ich Datensätze in PLANTA project?
- Wie rücke ich strukturierte Datensätze wieder aus?
- Warum kann ich Datensatz/-sätze mit Drag & Drop-Kopieren nicht auf einen leeren Datensatz kopieren?
- Kann weitergearbeitet werden, während die Sanduhr angezeigt wird?
- Kann weitergearbeitet werden, solange eine Dialogmeldung angezeigt und nicht bestätigt wird?
- Warum werden im Einfüge-Kontextmenü nicht nur untergeordnete Bereiche angezeigt?
- Warum kann ich in manchen Projekten/Vorgängen Änderungen vornehmen und in anderen nicht?
- Wann kommt die Meldung Nur Eingabe existierender Nummern erlaubt?
- Warum wirkt ein Filterkriterium nicht wie erwartet?
- Warum kommt beim Suchen im Modul die Meldung Invalid pattern: "+". "+" wird analysiert - Quantifizierer {x,y} nach nichts.?
Allgemeine FAQ
Wie finde ich am schnellsten die benötigten Informationen in der Dokumentation?
Durch Betätigen- der Taste F2 in einem Modul wird die Beschreibung zu dem aktiven Modul geöffnet
- der Taste F1 in einem Feld, wird die Beschreibung zu dem Feld geöffnet
- der Tasten STRG+M wird die Startseite der PLANTA-Online-Dokumentation geöffnet. Hier befindet sich das Inhalstverzeichnis, über welches man zu den weiteren benötigten Beschreibungen gelangen kann.
| Siehe auch: Arbeiten mit PLANTA-Wiki |
Wie finde ich die Beschreibung eines bestimmten Moduls?
Siehe die Antworten in der vorherigen FrageWo finde ich die ID eines Moduls?
- In das gewünschte Modul klicken und STRG + F2 (oder ? Modulinformation) betätigen.
- Das Modul Modulinformation öffnet sich.
- Links oben im Datenfeld MOD befindet sich die Modul-ID.
Ein Modul, das ich oft benutze, enthält viele Felder, die ich nicht brauche. Kann ich diese dauerhaft ausblenden?
Sie können von diesem Modul eine individuelle Modulvariante erstellen, in der Sie die von Ihnen nicht benötigten Felder ausblenden. Diese Variante können Sie als Favorit kennzeichnen, das bedeutet, dass beim Aufruf des Moduls standardmäßig Ihre Variante geladen wird.Wie kann man die Zeitskala zoomen?
| Horizontaler Skalen-Zoom | SHIFT + Scrollen |
| Vertikaler Skalen-Zoom | STRG + SHIFT + Scrollen |
| Siehe auch: Zoom-Funktion |
Wie strukturiere ich Datensätze in PLANTA project?
Datensätze werden in PLANTA project nicht mehr wie in Releases < 39 über die Menüpunkte Höher stufen bzw. Tiefer stufen, sondern mittels Verschieben mit Drag&Drop strukturiert.Wie rücke ich strukturierte Datensätze wieder aus?
Datensätze werden in PLANTA project mittels Verschieben mit Drag&Drop sowohl strukturiert, als auch wieder ausgerückt.Warum kann ich Datensatz/-sätze mit Drag & Drop-Kopieren nicht auf einen leeren Datensatz kopieren?
In Release 39 hat sich das Drag&Drop-Verhalten im Vergleich zu früheren Releases grundsätzlich verändert, u.a. wird für das Kopieren eines Datensatzes kein leerer Datensatz mehr benötigt und aufgrunddessen wird dies vom Programm nicht mehr unterstützt. Stattdessen kann der Datensatz einfach an die gewünschte Position kopiert werden, indem der Mauscursor an der entsprechenden Stelle losgelassen wird. Dabei wird automatisch ein neuer Datensatz angelegt. Wird trotzdem versucht, auf einen leeren Datensatz zu kopieren, kommt die Meldung Kopieren nicht möglich.| Siehe auch: Drag&Drop-Kopieren von Datensätzen |
Kann weitergearbeitet werden, während die Sanduhr angezeigt wird?
- Solange die Sanduhr angezeigt wird, können nur reine Client-Operationen ausgeführt werden, z.B. Wechsel in ein anderes Panel, Ändern der Werte in einem Feld, Anklicken einer Checkbox etc.
- Operationen wie Speichern, Öffnen eines weiteren Moduls, Schließen eines Moduls etc. sind jedoch nicht möglich.
- Sobald die Aktion, wegen der die Sanduhr angezeigt wurde, fertig ist, werden diese Operationen ausgeführt.
Kann weitergearbeitet werden, solange eine Dialogmeldung angezeigt und nicht bestätigt wird?
- Solange die Dialogmeldung nicht bestätigt wird, erscheint neben dem Cursor in allen Panels, in denen die Dialogmeldung nicht angezeigt wird, eine Sanduhr.
| Siehe auch: Kann weitergearbeitet werden, während die Sanduhr angezeigt wird? |
Warum werden im Einfüge-Kontextmenü nicht nur untergeordnete Bereiche angezeigt?
- Das liegt am Aufbau des Kontextmenüs.
- Dieses besteht aus zwei Bereichen:
- Der erste Abschnitt ist unabhängig davon, auf welchem Datenbereich das Kontextmenü geöffnet wird, immer gleich. In ihm wird/werden immer der oder die Datenbereich/e der obersten Ebene angezeigt, für die das Einfügen erlaubt ist.
- Ob der zweite Abschnitt erscheint und welche Bereiche darin angezeigt werden, hängt davon ab, ob der fokussierte Datenbereich und/oder seine untergeordneten Bereiche eingefügt werden können.
- Dieses besteht aus zwei Bereichen:
| Siehe auch: Einfügen |
Warum kann ich in manchen Projekten/Vorgängen Änderungen vornehmen und in anderen nicht?
Ob Änderungen in den Planungsobjekten vorgenommen werden können oder nicht, hängt von den für Ihren Benutzer definierten Rechten ab.Wann kommt die Meldung Nur Eingabe existierender Nummern erlaubt?
Die Meldung kommt, wenn in ein Feld mit automatischer Identnummer eine Nummer eingetragen wird, die in der Datenbank nicht existiert. Hinweis- Wird die gleiche Nummer ein zweites Mal eingetragen, wird die Meldung nicht noch einmal ausgegeben. Dies liegt daran, dass der Client nur neue Werte an den Server sendet und keine identischen.
Warum wirkt ein Filterkriterium nicht wie erwartet?
Die Ursache kann entweder das inkorrekte Setzen der Filterkriterien sein (z.B. in Strukturen) oder auch bestimmte Modul-Customizing-Einstellungen. Bitte überprüfen Sie Ihre Filterkriterien oder wenden Sie sich an Ihren Customizer.| Siehe auch: Filtern und Filterkriterien setzen |
Warum kommt beim Suchen im Modul die Meldung Invalid pattern: "+". "+" wird analysiert - Quantifizierer {x,y} nach nichts.?
Diese Meldung erscheint, wenn bei aktivierter Schaltfläche Reguläre Ausdrücke benutzen ein Quantifizierer (z.B. +, * etc. ) ohne voranstehenden Ausdruck in das Suchfeld eingetragen wird. Hinweis- Weitere Informationen zu Quantifizierern finden Sie hier.
| Siehe auch: Suchen im Modul |
Anwendungsfunktionen
- Anwendungs-FAQ
- Allgemein
- Was bedeuten beide Zahlen in der Statusmeldung Anzahl Datensätze: x (y verarbeitet)?
- Warum werden in Mastermeilenstein-Charts Mastermeilensteine im grauen Bereich angezeigt?
- Die Auslastungsdiagramme aktualisieren sich nicht bei allen übergeordneten Ressourcen, wenn ich eine Ressourcen von einer Abteilung in die andere verschiebe
- Was bedeutet die Fehlermeldung: Es konnte nicht vollständig kopiert werden. Grund: Datensatz bereits vorhanden!
- Wie kann ich als Abteilungsmanager die Arbeitsstunden meiner Mitarbeiter erfassen?
- Wie kann man in PLANTA project Abhängigkeiten zwischen Projekten abbilden?
- Wie kann man in PLANTA project einen Standardterminplan (eine Terminplanvorlage, ein Terminplan-Template) anlegen?
- Warum soll ich Stornobuchungen erfassen statt Ist-Werte oder Buchungsdatensätze zu löschen?
- Was bedeutet die Meldung Objektschutz: Löschen nicht möglich ?
- Soll-, Ist-, Rest-, Gesamt-Werte in PLANTA project
- Darf ich als Teilprojektmanager einen Statusbericht für mein Teilprojekt erstellen?
- Kann man die Freigabe eines Statusberichts aufheben?
- Kann ich eine Projekt-ID selbst vergeben oder die bestehende ID ändern?
- Wo und wie fixiert man einzelne Planungstände?
- Wie können Mitarbeiter ihre Arbeitsstunden auf Projekte erfassen?
- Kann ich mit PLANTA project meine Projekte auswerten?
- Wo kann ich mit PLANTA project Änderungsanträge verwalten?
- Wie kann ich herausfinden, welche Mitglieder (Stakeholder) mein Projekt auf deren Watchlist haben?
- Kann ich ein Projekt in Teilprojekte unterteilen?
- Wie kann ich in PLANTA project Meilensteine definieren ?
- Wie kann ich zu jeder Zeit des Projekts wissen, wie viel Geld wir verbraucht haben und wie viel wir noch zur Verfügung haben?
- Wo kann ich den Fortschritt (fachlichen Erledigungsgrad) im Projekt eintragen?
- Wofür werden Kostenarten und Kostenartengruppen verwendet?
- Wie können Ist-Kosten erfasst werden?
- können auch Fremdkosten (z.B. Personal- und Sachkosten) verbucht werden?
- Wie löscht man ein Teilprojekt?
- Wie verteilt man den Ressourcenaufwand von einer Abteilungsressource auf einzelne Mitarbeiterressourcen?
- Wie nehme ich eine Ressource in die Ressourcenstruktur auf?
- Wirkt sich das Ändern der fachlichen Projekt-ID global (also z.B. auch auf schon existierende Statusberichte) aus?
- Was versteht man unter einer Periode?
- Terminplan und Terminrechnung
- Warum weicht bei mir die Gesamtdauer, die im Sammelvorgang angezeigt ist, von der Summe der einzelnen Vorgänge ab?
- Warum werden im Terminplan bei bestimmten Vorgängen keine Kosten angezeigt, obwohl Kostenfelder derer Ressourcen gefüllt sind?
- Manche Vorgänge im Terminplan sind nach Berechnung rot eingefärbt. Was bedeutet das?
- Warum sind in meinem Balkenplan einige Meilensteine grün und einige rot gefärbt?
- Warum sind in meinem Balkenplan einige Meilensteine grün, obwohl ich keinen Puffer habe?
- Bei der Berechnung des Terminplans in einem bestimmten Projekt erscheint die Meldung Filterergebnis zu gross, bitte einschränken. Was tun?
- Warum werden beim Berechnen des Terminplans für manche Ressourcen keine Belastungs-Datensätze erzeugt, obwohl Aufwand-Rest eingetragen ist?
- Warum hat man nach der Terminrechnung unterschiedliche Projekt-Aufwandswerte in Modulen Terminplan und Budget?
- Was bedeutet die Meldung: Eine für diese Kapazitätsrechnung benötigte Ressource wird aktuell von einer anderen Kapazitätsrechnung verwendet
- Warum werden im Terminplan Belastungs-Datensätze mit Belastung-Ist = 0 angezeigt?
- In welcher Reihenfolge wird bei der Neuplanung berechnet?
- Warum wird die max. Belastung/Tag scheinbar ignoriert?
- Bei der termintreuen Planung sind Kalk. Ende des Vorgangs und Kalk. Ende der Ressource unterschiedlich
- Allgemein
Anwendungs-FAQ
Allgemein
Was bedeuten beide Zahlen in der Statusmeldung Anzahl Datensätze: x (y verarbeitet)?
- Die erste Zahl (x) steht für die Anzahl der tatsächlich angezeigten Datensätze im Modul
- Die zweite Zahl (y) steht für die Anzahl der in den Hauptspeicher geladenen Datensätze, die für die Anzeige der Daten im Modul benötigt werden.
- Besteht zwischen den beiden Zahlen eine extrem hohe Differenz in einem Modul, in dem man Performance-Beeinträchtigung beobachtet, soll das Customizing des Moduls überprüft werden.
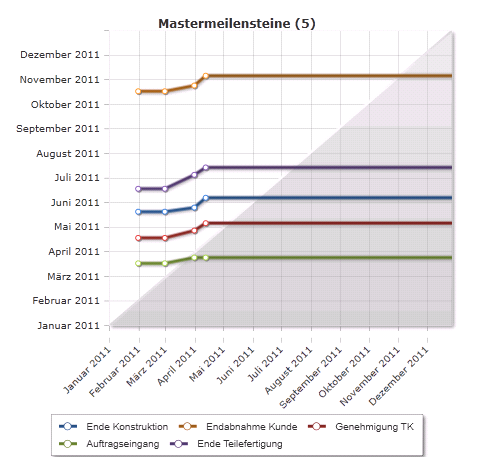
Warum werden in Mastermeilenstein-Charts Mastermeilensteine im grauen Bereich angezeigt?
Bei Verwendung des Modellparameters Aktive Heutelinie =
Beispiel
- Im Projekt wurden 2011 mehrere Stausberichte erstellt, danach wurde das Projekt eingefroren und erst 2014 wieder ein Statusbericht gemacht (der im Diagramm nicht mehr dargestellt werden kann). Wegen der nicht aktiven Heutelinie bleiben die kalkulierten Endtermine aber bestehen, und die Grafik zeigt die Linien dadurch in den grauen Bereich.
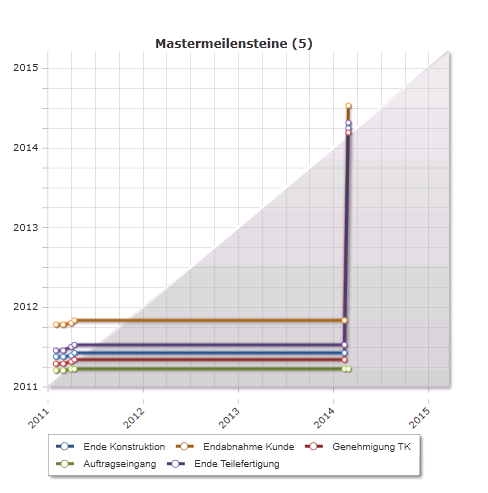
- Würde man für die Berechnung dieses Projekts jetzt den Modellparameter Heute berücksichtigen =
 setzen und nach erneuter Terminrechnung einen Statusbericht erstellen, würde die Trendanalyse so aussehen: die Termine des letzten Statusberichts sind wieder im weißen (positiven) Bereich:
setzen und nach erneuter Terminrechnung einen Statusbericht erstellen, würde die Trendanalyse so aussehen: die Termine des letzten Statusberichts sind wieder im weißen (positiven) Bereich:
- Möchte man die Termine im grauen Bereich ausblenden, dann kann im Modul Trendanalyse konfigurieren die Statusberichte für den ungewünschten Berichtszeitraum deaktivieren:
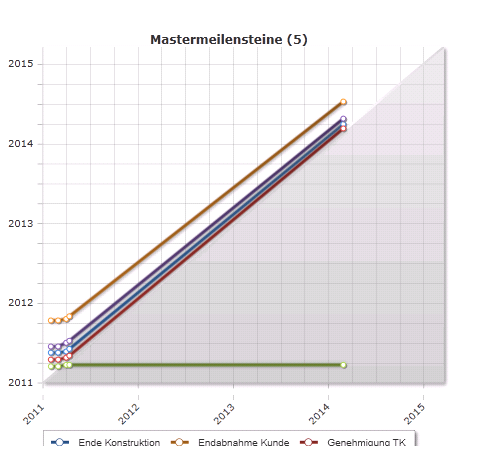
- Was übrig bleibt, sind Meilensteine mit Ist-Endtermin. Die Anzeige von Meilensteinen mit Ist-Endtermin wird ab 39.5.0 mittels Filterkriterium unterbunden
Die Auslastungsdiagramme aktualisieren sich nicht bei allen übergeordneten Ressourcen, wenn ich eine Ressourcen von einer Abteilung in die andere verschiebe
Dies liegt an der Ebene der übergeordneten Ressourcen. Mehr dazu finden Sie hier.Was bedeutet die Fehlermeldung: Es konnte nicht vollständig kopiert werden. Grund: Datensatz bereits vorhanden!
Die Meldung erscheint, wenn man versucht beim Kopieren mit Drag&Drop Datensätze das Kopierziel an der selben Stelle einzufügen, wo sich die Kopierquelle befindet, z.B. wenn man versucht beim Kopieren eines Ressourcenzuordnungs-Datensatzes diesen unter den gleichen Vorgang einzufügen.Wie kann ich als Abteilungsmanager die Arbeitsstunden meiner Mitarbeiter erfassen?
- Im Abteilungsboard im Modul Meine Abteilung den Link auf dem Namen des gewünschten Mitarbeiters anklicken. Damit wechselt man in das Mitarbeiterboard dieses Mitarbeiters. Von hier aus den Reiter Zeiterfassung betätigen, um das Modul Zeiterfassung aufzurufen. Im Modul Zeiterfassung die Stunden entsprechend Beschreibung erfassen.
- Auf die gleiche Art und Weise lässt sich auch Urlaub und Abwesenheit für Mitarbeiter der Abteilung im Modul Abwesenheit erfassen.
Wie kann man in PLANTA project Abhängigkeiten zwischen Projekten abbilden?
In PLANTA project gibt es drei M?glichkeiten, Abhängigkeiten zwischen Projekten abzubilden:- Durch das Einblenden externer Vorgänge in eigenen Terminplänen.
- Durch direkte Anlage der Abhängigkeiten zwischen Projekten.
- Durch Verbinden der Vorgänge unterschiedlicher Projekte über externe AOBs
Wie kann man in PLANTA project einen Standardterminplan (eine Terminplanvorlage, ein Terminplan-Template) anlegen?
Ein neues Projekt anlegen und einen Terminplan wie gewünscht erstellen. für dieses Projekt im Modul Projektsteckbrief im Feld Status den Status "Vorlage" auswählen. Dies bewirkt, dass dieses Projekt als Vorlageprojekt gespeichert und in der Kategorie Vorlagen zum Kopieren von Standardterminplänen angeboten wird. In Vorlageprojekten ist keine Terminrechnung möglich, sie werden in Auswertungen und Diagrammen nicht berücksichtigt.| Siehe auch: Tutorial: Projekt anlegen, planen und steuern |
Warum soll ich Stornobuchungen erfassen statt Ist-Werte oder Buchungsdatensätze zu löschen?
- Sind in Ihrem System automatische Stornobuchungen aktiviert, wie z.B. das in PLANTA-Standard der Fall ist, können Ist-Werte ohne Weiteres gelöscht bzw. korrigiert werden. Sind in Ihrem System automatische Stornobuchungen deaktiviert, müssen Sie für Ist-Werte, die gelöscht werden sollen, manuelle Stornobuchungen erfassen. Begründung:
- Werden im System Ist-Daten erfasst, werden bei der nächsten Berechnung der entsprechenden Projekte Rest-Daten angepasst. Das nachträgliche einfache Löschen/Ändern der bereits erfassten Ist-Daten kann die Nachvollziehbarkeit sowohl der Ist-Daten selbst als auch der Rest-Daten beeinträchtigen.
- Des Weiteren kann das nachträgliche einfache Löschen/Ändern von den bereits erfassten Ist-Daten in bestimmten Situationen, wie z.B. nach Übertrag an Fremdsysteme zu Problemen führen oder Differenzen im Ziel- und Quellsystemen als Folge haben.
- Vom Löschen der kompletten Buchungsdatensätze rät PLANTA ausdrücklich ab, auch wenn der Benutzer die dafür notwendigen Berechtigungen besitzt, da hier noch weitere Dateninkonsistenzen, als die bereits oben beschriebene, entstehen können.
| Siehe auch: Stornobuchungen |
Was bedeutet die Meldung Objektschutz: Löschen nicht möglich ?
Diese Meldung erscheint, wenn man versucht, Ist-Buchungsdatensätze oder ein Objekt mit Ist-Buchungsdatensätzen zu löschen, ohne die nötigen Berechtigung hierzu zu haben. Ab Version DB 39.5.7 wurde der Wortlaut der Meldung geändert auf: Sie haben keine Berechtigung zum Löschen von Ist-Buchungen.| Siehe auch: Berechtigungen zum Löschen von Buchungen |
Soll-, Ist-, Rest-, Gesamt-Werte in PLANTA project
In PLANTA project wird bei mehreren Objekten (wie z.B. bei Aufwand, Kosten etc.) und auf mehreren Ebenen (Projekt, Vorgang, Ressourcenzuordnung, Belastung) zwischen Soll-, Ist-, Rest und Gesamt-Werten unterschieden.- Soll-Werte sind die sogenannten Planwerte. Solange das Projekt sich in Planung befindet und keine Ist-Werte vorliegen, sind Soll-Werte = Rest-Werte. D.h. möchte man Planwerte vorgeben, trägt man diese in der Rest-Spalte ein. Die Wert wird automatisch in die Soll-Spalte übertragen, die defaultmäßig nicht sichtbar ist, jedoch bei Bedarf aus dem unsichtbaren Fenster eingeblendet werden kann. Sobald Ist-Werte vorhanden sind, werden die ursprünglichen Soll-Werte eingefroren und verändern sich nicht mehr. Somit ist der ursprüngliche Planwert für die evtl. späteren Vergleiche, Analysen, Änderungsverfolgung etc. verfügbar.
- Rest-Werte sind entweder Planwerte, solange das Projekt sich in Planung befindet, oder restliche Werte (das bedeutet um die Ist-Werte reduzierten Soll-Werte), sobald das Projekt gestartet ist und Ist-Werte vorliegen. Ob und auf welchen Ebenen Rest-Werte manuell erfasst werden können oder automatisch berechnet werden hängt von Objekten selbst ab, von der Projektebene sowie von bestimmten Projekteinstellungen.
- Ist-Werte sind tatsächliche Werte. Diese werden entweder manuell erfasst, z.B. Stunden im Rahmen der Arbeitszeiterfassung, oder automatisch berechnet, das hängt vom Objekt selbst und der Projektebene ab.
- Gesamt-Werte sind Summe von Rest und Ist und werden immer für alle Objekte auf allen Ebenen automatisch berechnet.
Darf ich als Teilprojektmanager einen Statusbericht für mein Teilprojekt erstellen?
Nein, die Funktion Statusberichte erstellen ist in strukturierten Projekten nur auf Hauptprojektebene und nur für Hauptprojektmanager verfügbar.Kann man die Freigabe eines Statusberichts aufheben?
Die Freigabe eines Statusberichts kann nur von einem Multiprojektmanager im Modul Kontrolle Statusberichtserstellung und Projektanträge aufgehoben werden.| Siehe auch: Statusbericht |
Kann ich eine Projekt-ID selbst vergeben oder die bestehende ID ändern?
Für Projekte und Vorgänge existieren in PLANTA project technische und fachliche IDs. Beide werden beim Erstellen der Projekte/Vorgänge automatisch erzeugt.- Die technischen IDs sind in den meisten Fällen verborgen und können nicht verändert werden.
- Die fachlichen IDs sind dagegen an der Oberfläche sichtbar und können von einem Benutzer mit Projektänderungsrechten jederzeit geändert werden.
- Die fachliche
- Projekt-ID wird im Modul Projektsteckbrief über die Schaltfläche Fachliche ID ändern (rechts im Modulkopfbalken) geändert.
- Vorgangs-ID wird im Modul Terminplan direkt im Feld Vorgang geändert.
- Die fachliche
| Siehe auch: Technische Projekt-ID, Fachliche Projekt-ID, Technische Vorgangs-ID, Fachliche Projekt-ID |
Wo und wie fixiert man einzelne Planungstände?
Ab DB 39.5.7
In PLANTA project werden einzelne Planungsstände in Statusberichten fixiert. D.h. pro Stand wird ein extra Statusbericht im Modul Status erstellt. Die Daten der Statusberichte können mit den aktuellen Projektdaten im Modul NEU Abweichungen verglichen werden.
Bis DB 39.5.7
In PLANTA project werden einzelne Planungsstände in Statusberichten fixiert. D.h. pro Stand wird ein extra Statusbericht im Modul Status erstellt. Die Daten der Statusberichte können mit den aktuellen Projektdaten im Modul Deltabetrachtung verglichen werden.
Wie können Mitarbeiter ihre Arbeitsstunden auf Projekte erfassen?
Die Seite Arbeitszeiterfassung bietet eine Übersicht über alle Varianten der Arbeitszeiterfassung in PLANTA. Sie finden dort Links auf alle relevanten Module.Kann ich mit PLANTA project meine Projekte auswerten?
PLANTA project bietet umfangreiche Auswertungsmodule, um einen schnellen Überblick über die Projekte zu erhalten, z.B. das Multiprojektboard, die Kostenübersichten und die Ressourcenübersichten.Wo kann ich mit PLANTA project Änderungsanträge verwalten?
Im Modul Änderungsantrag können Änderungsanträge neu angelegt und bearbeitet werden. Erledigte Änderungsanträge werden ebenfalls angezeigt.Wie kann ich herausfinden, welche Mitglieder (Stakeholder) mein Projekt auf deren Watchlist haben?
Ab DB 39.5.7
Im Modul NEU Dashboard werden im Bereich Dieses Projekt ist auf der Watchliste von: die Personen aufgelistet, die das aktuelle Projekt in die eigene Watchliste für die Beobachtung aufgenommen haben.
Bis DB 39.5.7
Im Modul Stakeholder werden im Bereich Dieses Projekt ist auf der Watchliste von: die Personen aufgelistet, die das aktuelle Projekt in die eigene Watchliste für die Beobachtung aufgenommen haben.
Kann ich ein Projekt in Teilprojekte unterteilen?
Im Modul Teilprojekte können einem Projekt ein oder mehrere Projekte zugeordnet werden.| Siehe auch: Projekte strukturieren |
Wie kann ich in PLANTA project Meilensteine definieren ?
Bei PLANTA project wird zwischen Meilensteinen und Mastermeilensteinen unterschieden. Im Modul Terminplan kann mit dem Parameter Meilenstein pro Vorgang bestimmt werden, ob dieser ein einfacher Vorgang, ein Meilenstein-Vorgang oder ein Mastermeilenstein-Vorgang ist.Wie kann ich zu jeder Zeit des Projekts wissen, wie viel Geld wir verbraucht haben und wie viel wir noch zur Verfügung haben?
Im Modul Budget werden Kosten, Aufwand und Budgets (Aufwand und Kosten) des Projekts angezeigt und bearbeitet. Nach Abschluss der Budgetplanung bei Projektbeginn kann im Modul Status ein Statusbericht erstellt werden. Dieser Statusbericht kann dann mit anderen Planungsständen im Modul Abweichungen verglichen werden.Wo kann ich den Fortschritt (fachlichen Erledigungsgrad) im Projekt eintragen?
Im Modul Fortschritt kann der Projektleiter den Fortschritt pflegen.Wofür werden Kostenarten und Kostenartengruppen verwendet?
- Sowohl Kostenarten als auch Kostenartengruppen dienen der Gliederung der Kosten.
- Kostenarten werden für eine feine Kostenskalierung verwendet.
- Mehrere Kostenarten können zu Gruppen zusammengefasst werden und bilden somit die Kostenartengruppen, grobe Kostenskalierung.
- In PLANTA project-Standard-Modulen werden Kosten verteilt auf Kostenartengruppen dargestellt.
| Siehe auch: Kostenarten, Kostenartengruppen |
Wie können Ist-Kosten erfasst werden?
- Bei allen Ressourcen mit Ressourcenart ≠ 8 und ≠ 9 werden die Ist-Kosten automatisch vom Programm auf der Bass von erfassten Arbeitsstunden (Aufwand-Ist) der Ressourcen und deren Umrechnungsfaktoren berechnet.
- für Ressourcen mit Ressourcenart = 8 und 9 (Erlös- und Kostenressourcen) werden Ist-Kosten manuell in den Modulen Erlöse buchen und Kosten buchen gebucht.
können auch Fremdkosten (z.B. Personal- und Sachkosten) verbucht werden?
In PLANTA project werden berechnete oder erfasste Kosten auf Kostenartengruppen aufgeteilt.Um Fremdkosten zu verbuchen:
- Eine Kostenartengruppe Fremdkosten erfassen.
- Eine oder beliebig viele Kostenarten anlegen, denen die Kostenartengruppe Fremdkosten zugeordnet wird.
- Eine oder beliebig viele Kostenressourcen (Ressourcen mit der Ressourcenart = 9) anlegen, denen die Kostenarten aus der Kostenartengruppe Fremdkosten zugeordnet werden.
Wie löscht man ein Teilprojekt?
Zum Löschen eines Teilprojekts bestehen folgende Möglichkeiten:- Entweder man löst das gewünschte Teilprojekt aus der Struktur des Hauptprojekts heraus und löscht das gelöste Projekt anschließend wie ein selbstständiges Projekt.
- Oder man löscht ein Teilprojekt aus dem Hauptprojekt heraus.
Wie verteilt man den Ressourcenaufwand von einer Abteilungsressource auf einzelne Mitarbeiterressourcen?
Ressourcenaufwände werden im Modul Einplanungen verteilt.Wie nehme ich eine Ressource in die Ressourcenstruktur auf?
Im Modul Ressourcendatenblatt wird eine Ressourcenstruktur gebildet und geändert.- Im Ressourcendatenblatt der Ressource, die untergeordnet werden soll, im Feld Übergeordnete Ressource eine übergeordnete Ressource auswählen.
Wirkt sich das Ändern der fachlichen Projekt-ID global (also z.B. auch auf schon existierende Statusberichte) aus?
In den Globale Einstellungen kann mit dem Parameter change_project_functional_global eingestellt werden, ob die fachliche ID global (also z.B. auch in schon existierenden Statusberichten) geändert werden soll. Wenn der Wert = 1 ist, wird die Änderung global übernommen.| Siehe auch: Fachliche ID ändern |
Was versteht man unter einer Periode?
In PLANTA project entspricht eine Periode einem Datum.- An diesem Datum kann eine Ressource z.B. eingeplant oder Urlaub oder Abwesenheiten können für sie hinterlegt werden.
- Perioden (Perioden-Datensätze) werden durch das Festlegen eines Periodenzeitraums in den Feldern Start- und Endperiode in Modulen Ressourcendatenblatt oder Ressourcen automatisch generiert und können im Modul Verfügbarkeit eingesehen und bei Bedarf bearbeitet werden. Detaillierte Informationen zum Anlegen, Bearbeiten und Löschen von Perioden siehe in der Beschreibung des Moduls Ressourcendatenblatt.
Terminplan und Terminrechnung
Warum weicht bei mir die Gesamtdauer, die im Sammelvorgang angezeigt ist, von der Summe der einzelnen Vorgänge ab?
Die Ursache dafür kann eine der folgenden sein:- Hat einer der zur Berechnung hinzugezogenen Vorgänge die Dauer = 0 und ist in den Modellparametern der Parameter Anfang VG-Nachfolger + 1 T deaktiviert, startet der Vorgang, der demjenigen mit Dauer = 0 folgt, am selben Tag. Somit ist die berechnete Zahl für die tatsächliche Dauer kleiner als die Summe, die sich aus der Berechnung von einzelnen Vorgängen ergibt.
- Wird der Parameter Anfang VG-Nachfolger + 1 T aktiviert, startet der Vorgang, der demjenigen mit der Dauer = 0 folgt, einen Tag später. Somit werden die angezeigte Gesamtdauer und die Summe aus einzelnen Vorgängen gleich sein.
Warum werden im Terminplan bei bestimmten Vorgängen keine Kosten angezeigt, obwohl Kostenfelder derer Ressourcen gefüllt sind?
Kosten der Ressourcen mit der Ressourcenart = 8 (Erlösressourcen) werden nicht auf die Vorgangsebene verdichtet.Manche Vorgänge im Terminplan sind nach Berechnung rot eingefärbt. Was bedeutet das?
Sobald bei der Berechnung eines Terminplans ein Netzplanzyklus entdeckt wird, werden die betroffenen Vorgänge farblich hervorgehoben (rot eingefärbt) und die Terminrechnung wird abgebrochen. Der Zyklus muss durch die Korrektur der Anordnungsbeziehungen behoben werden, weil ansonsten keine Berechnung des Terminplans möglich ist. Im Modul Zyklensuche sind alle Projekte aufgelistet, die einen Zyklus aufweisen.Ein Netzplanzyklus entsteht, wenn bei der Berechnung eines Terminplan innerhalb des Netzplans kein letzter Vorgang gefunden werden kann.
Warum sind in meinem Balkenplan einige Meilensteine grün und einige rot gefärbt?
Die Farbe des Meilensteinsymbols wird durch den Puffer bestimmt. Meilensteine mit negativem Puffer werden rot dargestellt, Meilensteine mit Puffer = 0 oder positivem Puffer werden grün angezeigt.- Der Puffer wird durch die Terminrechnung aufgrund der Konstellation bestimmter Faktoren (AOBs, Dauer, Wunsch-Termine etc.) berechnet.
- Um den Puffer zu sehen, müssen die entsprechenden Datenfelder per Customizing sichtbar gemacht werden.
| Siehe auch: Legende im Modul Terminplan |
Warum sind in meinem Balkenplan einige Meilensteine grün, obwohl ich keinen Puffer habe?
Bei Meilensteinen gilt Puffer = 0 als unkritisch, somit werden solche Meilensteine grün angezeigt. Nur Meilensteine mit negativem Puffer werden rot angezeigt.| Siehe auch: Legende im Modul Terminplan |
Bei der Berechnung des Terminplans in einem bestimmten Projekt erscheint die Meldung Filterergebnis zu gross, bitte einschränken. Was tun?
Diese Meldung signalisiert, dass zu viele Datensätze beim Berechnen eines Terminplans verarbeitet werden müssen. Um die Anzahl der zu verarbeitenden Datensätze zu verringern, können folgende Maßnahmen getroffen werden, z.B.:- Prüfen, ob Zahlendreher in den Rückmeldungen vorhanden sind (z.B. das Jahr 21 statt 12) .
- Den Planungshorizont des Projekts verringern, z.B. bei unnötig langen Durchlaufzeiten.
- Falls der lange Planungshorizont nicht verringert werden kann, Projekte auf mehrere Projekte aufteilen.
- Die Anzahl der Perioden der Ressource reduzieren (d.h. Start-Periode und/oder End-Periode ändern).
- Die Belastungskurven in dem Projekt von BLD auf z.B. Week umstellen.
Warum werden beim Berechnen des Terminplans für manche Ressourcen keine Belastungs-Datensätze erzeugt, obwohl Aufwand-Rest eingetragen ist?
- Bei Ressourcenzuordnungen mit der Belastungskurve MAN erfolgt die Planung im Modul Terminplan auf der Belastungsebene manuell im Feld Belastung-Rest (DT472). Hierzu werden Belastungsdatensätze manuell erzeugt. Die manuell eingetragenen Werte werden bei der Berechnung des Terminplans nach oben auf die Ebenen Ressourcenzuordnung (DT466), Vorgang (DT463) und Projekt (DT461) automatisch verdichtet.
- Bei Ressourcenzuordnungen mit anderen Belastungskurven erfolgt die Planung im Modul Terminplan auf der Ressourcenzuordnungsebene im Feld Aufwand-Rest (DT466). Die eingetragenen Wert werden bei der Berechnung nach oben auf die Ebenen Vorgang (DT463) und Projekt (DT461) automatisch verdichtet und nach unten auf die Ebene Belastung auf die einzelnen Belastungsdatensätze in DT472 entsprechend der auf der Ressourcenzuordnung eingetragenen Belastungskurve verteilt.
- Wird bei der Ressourcenzuordnung mit der Belastungskurve MAN der Aufwand inkorrekterweise auf der Ressourcenzuordnungs-Ebene eingetragen, wird er nur nach oben verdichtet, aber nicht nach unten auf die Belastungsebene verteilt.
Warum hat man nach der Terminrechnung unterschiedliche Projekt-Aufwandswerte in Modulen Terminplan und Budget?
Weisen eine oder mehrere Ressourcenzuordnungen im Terminplan die Belastungskurve MAN auf und wurde für diese der Aufwand inkorrekterweise auf der Ressourcenzuordnungsebene (im Feld Aufwand-Rest (DT466)) geplant, anstatt auf der Belastungsebene (im Feld Belastung-Rest (DT472)), unterscheiden sich die Projekt-Aufwands-Werte im Modul Budget von den Werten im Modul Terminplan.- Begründung
- Modul Terminplan: Die Projektwerte DT461 verdichten sich aus den Werten DT463 Vorgang, diese wiederum aus DT466 Ressourcenzuordnung und diese aus DT472 Belastung.
- D.h.: Gibt es keine Werte in der DT472 Belastung, aber in DT466 Ressourcenzuordnung, werden diese von DT466 Ressourcenzuordnung in die DT463 Vorgang und anschließend in die DT461 Projekt verdichtet.
- Modul Budget: Die Projektwerte DT282 Projekt/Jahr/KoAGr bzw. DT281 Projekt/Kostenartengruppe berechnen sich direkt auf Basis der DT472 Belastung. Weist die DT472 keine Werte auf, wird es auch im Modul Budget nichts ausgewiesen.
- Modul Terminplan: Die Projektwerte DT461 verdichten sich aus den Werten DT463 Vorgang, diese wiederum aus DT466 Ressourcenzuordnung und diese aus DT472 Belastung.
| Siehe auch: Termin-, Ressourcen- und Kostenplanung |
Was bedeutet die Meldung: Eine für diese Kapazitätsrechnung benötigte Ressource wird aktuell von einer anderen Kapazitätsrechnung verwendet
Das beutet, dass gleichzeitig ein weiterer Terminrechnungsvorgang läuft (angestoßen von einem anderen Benutzer), bei dem ein oder mehrere Projekte berechnet werden, in denen eine oder mehrere Ressourcen vorkommen, die auch im Projekt vorkommen, das ich gerade berechnen möchte. Da die gleichen Ressourcen nicht gleichzeitig von mehreren Terminrechnungen berechnet werden können, hat die den Vorrang, die früher angestoßen wurde. In diesem Fall soll man kurz warten und die Terminrechnung nochmal anstoßen. Hinweis- Ab Version DB 39.5.11 wurde die Meldung wie folgt geändert: Eine Ihrer Ressourcen wird gerade in der Berechnung eines anderen Projektes verwendet. Bitte führen Sie die Berechnung in wenigen Sekunden nochmals durch!
Warum werden im Terminplan Belastungs-Datensätze mit Belastung-Ist = 0 angezeigt?
- Der Grund hierfür ist, dass bei einer bestehenden Zeiterfassung im gleichnamigen Modul unter der Skala der Wert 0 eingetragen bzw. dieser gelöscht wurde. Dabei wird der Belastungs-Datensatz nicht gelöscht, sondern nur der Wert im Feld Belastung-Ist geändert.
- Erst die Terminrechnung löscht diese Belastungsdatensätze, d.h. nach einer Terminrechnung werden diese auch im Terminplan nicht mehr angezeigt.
In welcher Reihenfolge wird bei der Neuplanung berechnet?
Die Neuplanung wird im Modul Neuplanung (Berechnung aller Planungsobjekte) dzrchgeführt.- Die in diesem Modul angezeigten Planungsobjekte werden in folgender Reihenfolge berechnet:
Warum wird die max. Belastung/Tag scheinbar ignoriert?
Details- Die Terminrechnung belastet einen Vorgang mit mehr als dem Wert max. Belastung/Tag
- Obwohl die Terminrechnung diesen Vorgang damit überlastet, wird keine Überlast angezeigt.
- Beabsichtigtes Softwareverhalten
- Der Wert max. Belastung/Tag ist für die Terminrechnung eine gewünschte Grenze, die überschritten wird, wenn dies erforderlich ist.
- Eine Überschreitung der Grenze max. Belastung/Tag ist noch keine Überlastung, da eine Überlastung nur auf Grund der verfügbaren Kapazität einer Ressource ermittelt wird.
- Die Terminrechnung arbeitet mit dem Parameter max. Belastung/Tag wie folgt:
- Die gewünschte Zeitrechnungs-Dauer des Vorgangs wird errechnet aus Aufwand/ max. Belastung/Tag.
- Diese Dauer ist der Ausgangswert für den Kapazitätsabgleich.
- Die Terminrechnung versucht beim Kapazitätsabgleich, in der verfügbaren Dauer (gewünschte Dauer + Puffer) die Ressource nur bis zu dem Wert max. Belastung/Tag zu belasten. Ist dies nicht möglich, wird der verbleibende Aufwand gleichmäßig über die verfügbare Dauer eingelastet, auch dann, wenn dabei die Perioden der Ressource Überlastet werden.
Bei der termintreuen Planung sind Kalk. Ende des Vorgangs und Kalk. Ende der Ressource unterschiedlich
Dieser Fall kann auftreten, wenn die Einplanung der betroffenen Ressource mit der Belastungskurve CAP über ihren Planungshorizont hinausgeht (d. h. später als ihre Endperiode ist). In diesem Fall plant die Terminrechnung auf der Ressourcenzuordnungs-Ebene alle restlichen Stunden, die sie im Planungshorizont nicht unterbringen konnte auf einen Tag ein, und zwar auf den ersten Tag nach der Endperiode der Ressource, während die Aufteilung auf dem Vorgang nach Ende des Planungshorizonts linear verläuft, bis alle übrigen Stunden verplant sind. Lösungsalternativen- 1: Verlängern des Planungshorizonts (Endperiode) der Ressource im Ressourcendatenblatt.
- 2: Einplanung der Ressource mit der Belastungskurve MAN.
Customizing
- Customizing-FAQ
- Allgemeines
- Was ist Python?
- Warum Python?
- Wo finde ich die Beschreibung der Python-Funktionen, die PLANTA bereitstellt?
- Was ist der DTP?
- Was ist ein MTS Record?
- Wie wird die I-Nummer für einen I-Text generiert?
- Hat sich etwas bei den I-Texten im Vergleich zu Releases < 39 geändert?
- Warum wird keine automatische Nummer erzeugt?
- Einstellungen
- Wie richte ich die PLANTA-E-Mail-Funktion (um E-Mails direkt zu versenden) ein?
- Wie kann man den Systemtitel ändern?
- Wie kann man den Editor ändern, der zum Bearbeiten von Makros, Wertebereichen etc. benutzt wird?
- Wie kann ich ein eigenes Produktlogo (Firmenlogo) hinterlegen bzw. systemweit einsetzen?
- Fragen zum Verhalten ("Warum?")
- Warum wird ein DI in einem Modul nicht angezeigt?
- Warum wird ein neu gecustomiztes Kontextmenü nicht angezeigt?
- In welchem Verhältnis stehen die Größen Feldbreite, Einrückung und Breite Fenster 1, 2 und 3 zueinander?
- Was sind implizite Hol-Exits?
- Warum werden Felder in einem neuen Fenster nicht angezeigt?
- Woran liegt es, dass eingetragene und gespeicherte Werte unter der Skala nach einem Neustart verschwunden sind?
- Warum kann man ein neu angelegtes DI nicht verwenden/Warum wirken Änderungen am DI nicht?
- Warum kann aus einer Listbox kein Wert ausgewählt werden?
- Warum kann ich im Maskeneditor, obwohl der Customizing-Modus aktiviert ist, keine Felder anklicken?
- Warum werden alternierende Schattierungen schwarz angezeigt?
- Warum wirkt ein Filterkriterium in rekursiven Strukturen nicht wie erwartet?
- Warum wirkt ein Filterkriterium nicht?
- Warum werden die Charts in einem kopierten Modul nicht angezeigt?
- Warum kann in einem Hyperlink-Feld eine aus der Vorlage einkopierte Datei nicht geöffnet werden?
- Warum wird nach Ändern einer Variable, diese nicht mehr abgeändert im System angezeigt, nachdem der Client neugestartet wurde?
- Warum kann in einem Hyperlink-Feld eine aus der Vorlage einkopierte Datei nicht geöffnet werden?
- Customizing-Tipps ("Wie?")
- Was kann ich tun, um die Performance zu verbessern?
- Wie müssen Pfade in der Python-Funktion client_exec() angegeben werden?
- Wie sind die Währungsformate standardmäßig gecustomized?
- Wie wird die Höhe und Breite von Listboxen eingestellt?
- Wie können Zeilenumbrüche in einem Datenfeld eingestellt werden?
- Wie wird der (im Standard blaue) Rahmen um eine Listbox gecustomized?
- Wie kann der Inhalt der aktuellen @L-Variablen (Listenvariablen) angezeigt werden?
- Wie kann der Inhalt einer bestimmten Variablen angezeigt werden?
- Wie kann die Ausrichtung des Datenfeldinhalts geändert werden?
- Wie kann man die Performance beim Customizen der Ressourcenstruktur verbessern?
- Wie kann man ein neu aufgerufenes Untermodul als Reiter hinter dem Hauptmodul customizen?
- Wie kann ich einen Datensatz aus dem DTP auslesen bzw. aus der Datenbank in den Pool holen?
- Wie kann man zwei (oder mehr) Datenfelder hinter einem Balken anzeigen?
- Wie kann ich ein Datenfeld ohne Überschrift anzeigen lassen?
- Customizen in zwei Sessions
- STRG + F3 zum Öffnen des aktuellen Datenbereichs/F9 zum Öffnen des Moduls
- Automatisches Anlegen von Inkarnationen
- Round Wertebereiche aus Performancegründen in computeSqlValueRange()-Wertebereiche umwandeln
- Python: Wie füge ich Elemente zu einer Liste hinzu?
- Wie kann ich die Funktion Terminplan kopieren erweitern?
- Wie kann das Summenzeichen Σ angezeigt werden?
- Wie kann ich ein individuelles Benutzermenü einbinden?
- Wie kann der Splash Screen ausgetauscht werden?
- Wie können Texte in E-Mails, z.B. Signaturen, geändert werden?
- Meldungen
- Was bedeutet die Meldung Achtung: Ihre Änderung an einer Customizing-Tabelle erzwingt ein Update der Java-Pojo-Klassen. Bitte informieren Sie die Serverentwicklung!
- Was bedeutet die Meldung IE: (MV creation/application/saving) "[Modulvarianten-ID]" uses these unsupported DIs:DI[Dataitem-ID]
- Beim Customizen eines Python-Wertebereichs kommt eine Fehlermeldung. Was bedeutet sie?
- Was bedeutet die Fehlermeldung: Python error in macro [Makro-ID]. Class 'SyntaxError': ("Non-UTF-8 code starting with...)
- Warum kommt beim Starten eines Moduls die Meldung Skalenzuordnung nicht möglich: MOD [Modul-ID], DA [Datenbereichs-ID], horizontal bar DF [Datenfeld-ID] (DI [Dataitem-ID])?
- Abbilden von Funktionen aus Releases 3.8 in PLANTA project
- Allgemeines
Customizing-FAQ
Allgemeines
Was ist Python?
Python ist eine Programmiersprache, die mehrere Programmierparadigmen ermöglicht. So werden objektorientierteWarum Python?
Python hat eine wunderbar einfache Syntax und lässt sich extrem gut in C integrieren.Wo finde ich die Beschreibung der Python-Funktionen, die PLANTA bereitstellt?
Die Funktionen werden in der Python-API beschrieben.Was ist der DTP?
DTP bedeutet Data Table Pool. Die PLANTA-Software legt dort alle aus der Datenbank geladenen (z.B. per Modul-Suche oder mit den Python-Funktionen: search_record, get_children etc.) Datensätze ab. Die Datensätze werden dann dort zur Darstellung in einem oder mehreren Modulen vorgehalten.Was ist ein MTS Record?
MTS bedeutet Module Tree Structure.- MTS Records sind Moduldatensätze, d.h., die Datensätze, die im Modul angezeigt werden.
- Zu jedem MTS Record gehört genau ein DTP Record.
- Beispiel: Ein Projekt mit all seinen Feldern
Wie wird die I-Nummer für einen I-Text generiert?
PLANTA generiert anhand des Eintrages in der schemaspezifischen Zählerstandtabelle eine neue I-Nummer für einen I-Text. Abhängig von der Lizenz und des I-Nr. DIs, wird der Wert des Zählerstand 1 DIs ausgelesen und für einen neuen I-Text genommen.- Beispiel für Q2B
- Zählerstandtabelle: DT 396 Zählerstand Q2B
Lizenzdataitem: DI 008150 Lizenz = Kundenlizenz
DI-Dataitem: DI 008152 DI = 000985 (I-Nr. DI aus der DT434 I-Nr. Q2B)
Zählerstanddataitem: DI 008164 Zählerstand 1
- Zählerstandtabelle: DT 396 Zählerstand Q2B
Hat sich etwas bei den I-Texten im Vergleich zu Releases < 39 geändert?
I-Texte werden in PLANTA project nur noch in der schemaspezifischen I-Text-Tabelle abgelegt. Die I-Nummern-Tabelle wird nicht mehr gepflegt und befüllt.Warum wird keine automatische Nummer erzeugt?
Eine automatische Nummer wird erst erzeugt, wenn alle DIs des Fremdschlüssels des Datensatzes mit gültigen Werten und, falls vorhanden, alle Muss-Datenfelder gefüllt sind. HinweisAb DB 39.5.0
- Ein Datensatz mit NULL-Wert ist nur dann ein gültiger Wert, wenn für die entsprechende Datentabelle der Parameter NULL erlaubt aktiviert ist (die Änderung ist nur durch PLANTA möglich).
Bis DB 39.5.0
| Siehe auch: Automatische Nummern, Muss-Datenfelder, Customizing von Muss-Datenfeldern |
Einstellungen
Wie richte ich die PLANTA-E-Mail-Funktion (um E-Mails direkt zu versenden) ein?
Im Modul Globale Einstellungen muss die richtige IP-Adresse des smtp-Servers bei der globalen Einstellung smtp_server_adress im Feld Alpha (120) eingetragen werden. Weitere InformationenWie kann man den Systemtitel ändern?
Der Systemtitel (im Titelbalken/Titelleiste) wird im Modul Lizenz, Systemparameter und DB-Instanzen im Feld Systembezeichnung hinterlegt und kann dort geändert werden. Hinweis- Alternativ kann auch zur Laufzeit der Systemtitel mit der folgenden Python-Funktion geändert werden:
ui_set_system_title(title: string)
| Siehe auch: Python API |
- Zur Auseinanderhaltung von verschiedenen Sessions können z.B. der aktuell angemeldete Benutzer und die PID im Systemtitel angezeigt werden.
- Wird das Standard-Benutzermenü MOD0099QC verwendet:
- Das Modul Pythonmakros öffnen und in der
on_load-Methode die VariableCHANGE_TITLEvonCHANGE_TITLE=FALSEaufCHANGE_TITLE=TRUEändern.
- Das Modul Pythonmakros öffnen und in der
- Wird ein individuelles Benutzermenü verwendet:
- Das Modul Pythonmakros öffnen und in der
on_load-Methode des Benutzermenüs folgende Zeilen einfügen: - Die folgenden Zeilen müssen, wie auch die anderen Zeilen in der
on_load-Methode, mit jeweils vier Leerzeichen eingerückt werden.
- Das Modul Pythonmakros öffnen und in der
- Wird das Standard-Benutzermenü MOD0099QC verwendet:
DetailsPID = str(os.getpid()) ppms.ui_set_system_title('Systemtitel' + ', PID: ' + PID + " - " + ppms.uvar_get("@1"))
- Ab dem nächsten Start von PLANTA project wird die PID im Systemtitel angezeigt.
- Die PID ist auch Bestandteil des Logfiles, sodass ein Logfile immer der entsprechenden Session zugeordnet werden kann.
Wie kann man den Editor ändern, der zum Bearbeiten von Makros, Wertebereichen etc. benutzt wird?
In mehreren Modulen kann über einen Schaltfläche ein Editor aufgerufen werden, z.B. im Modul Module über den Schaltfläche Python-Makrobearbeitung aufrufen. Welcher Editor dabei verwendet wird, wird in der globalen Einstellung py_editor im Modul Globale Einstellungen hinterlegt. Wird dort ein falscher Pfad angegeben, kommt die Meldung „Error executing python script: Das System kann die angegebene Datei nicht finden“.Wie kann ich ein eigenes Produktlogo (Firmenlogo) hinterlegen bzw. systemweit einsetzen?
- Um pro Modul ein individuelles Produktlogo zu hinterlegen:
- Im Modul OLEs ein neues OLE-Objekt für das Produktlogo anlegen.
- Für das gewünschte Modul im Modul Weitere Modulparameter im Feld Produktlogo die Identnummer des neu angelegten OLE-Objekts eintragen.
- Um das Logo in der Kopfzeile (Druckkopf) in den Standarddruckbereichen auszutauschen:
- Den Datenbereich mit Positionierung = 3 (Druckbereich: Kopfzeile) des Moduls, das im Skin des angemeldeten Benutzers im Datenfeld Modul für Druckber. hinterlegt ist, aufrufen.
- Dort die Identnummer des OLE-Objekts mit der des neu angelegten OLE-Objekts ersetzen.
- Das Logo in individuellen Druckbereichen muss ggf. genauso ausgetauscht werden.
- Um das eigene Produktlogo systemweit einzusetzen:
- Ein neues OLE-Objekt für das Produktlogo anlegen und der Kategorie Produktlogos zuordnen.
- In die Modulvariante Produktlogos wechseln.
- Bei dem neu angelegten OLE-Objekt die Schaltfläche Systemweit als Logo verwenden betätigen.
Fragen zum Verhalten ("Warum?")
Warum wird ein DI in einem Modul nicht angezeigt?
Ab S 39.5.0
- Das DI ist in Fenster 9.
- Das DI ist in einer Maske ohne Maskenposition.
- NEU Das DI ist ist virtuell und deaktiviert (Aktiviert (DT412) =
 ), die Datentabelle, in der sich das DI befindet, ist deaktiviert (Aktiviert (DT415) = ) oder das Schema, in dem sich das DI befindet, ist deaktiviert (Aktiviert (DT420) = ).
), die Datentabelle, in der sich das DI befindet, ist deaktiviert (Aktiviert (DT415) = ) oder das Schema, in dem sich das DI befindet, ist deaktiviert (Aktiviert (DT420) = ).
Bis S 39.5.0
Warum wird ein neu gecustomiztes Kontextmenü nicht angezeigt?
Das entsprechende Datenfeld muss in einem der sichtbaren Fenster (Fenster 1-3) gecustomized werden.| Siehe auch: Kontextmenü customizen |
In welchem Verhältnis stehen die Größen Feldbreite, Einrückung und Breite Fenster 1, 2 und 3 zueinander?
- Die Werte für DF-Breite und Einrücken werden in der gleichen Einheit, in Zehntelmillimetern angegeben.
- Die Angabe in Breite F1 etc. ist keine Größenangabe, sondern dient lediglich zur Berechnung des Anteils des Fensters an der gesamten Bildschirmbreite.
- Da die Breite von Bildschirmen (und damit die dem Panel „zur Verfügung stehende Breite“) unterschiedlich ist, ist dies kein fest definierter Wert.
Was sind implizite Hol-Exits?
Für den Fall, dass Daten aus übergeordneten Datentabellen angezeigt werden sollen, muss kein Exit gecustomized werden, es kann einfach das Dataitem selbst in den Datenbereich mit aufgenommen werden. Dies wird impliziter Hol-Exit genannt.| Siehe auch: Exits |
Warum werden Felder in einem neuen Fenster nicht angezeigt?
Soll ein Feld im Fenster 2 (bzw. Fenster 3) angezeigt werden, muss zusätzlich im Modul Weitere Modulparameter ein Wert im Datenfeld Breite F2 (bzw. Breite F3) eingetragen werden.- Beim Anlegen eines neuen Moduls im Modul Module wird über einen Standardwert in Breite F1 eine Breite für das Fenster 1 festgelegt, daher muss hier nicht explizit eine vergeben werden.
- Wenn das Feld Breite Fx (Breite F1, Breite F2, Breite F3) gefüllt ist, aber im Modul kein Datenfeld Fenster = x hat, wird Fenster x trotzdem (leer) angezeigt.
Woran liegt es, dass eingetragene und gespeicherte Werte unter der Skala nach einem Neustart verschwunden sind?
Bei Modulen, bei denen eine Eingabe in eine Projektion möglich sein soll, muss geprüft werden, ob im Datenbereich, der die Projektions-Dataitems enthält, der Parameter Ausgabe deaktiviert ist. Wenn nicht, kann der Wert nicht gespeichert werden (er wird angezeigt, aber nach Neustart sieht man, dass er nicht gespeichert wurde).Warum kann man ein neu angelegtes DI nicht verwenden/Warum wirken Änderungen am DI nicht?
Nach jeder Änderung an Dataitems der Systemdatenbanken (Schemas Q1 und Q2) muss der Server neugestartet werden. Im Data Dictionary und im Dataitems gibt es dafür die Schaltfläche Server-Neustart.- Ausnahme ist eine Änderung an
- I-Texten z.B. der DI-Bezeichnung oder
- Wertebereichen (auch der WB-Art)
- Metadaten zum Data Dictionary sind im Verzeichnis target enthalten. Die dafür verantwortlichen POJO-Klassen werden durch den Neustart des PLANTA-Dienstes nicht neu generiert. Das target-Verzeichnis muss gelöscht werden, damit die POJO-Klassen beim nächsten Neustart des PLANTA-Dienstes neu generiert werden.
Warum kann aus einer Listbox kein Wert ausgewählt werden?
Bei dem Wert, der aus der Listbox übernommen werden soll, muss im Listboxmodul der Parameter LB: Wertübernahme aktiviert sein. Tipp- Über den Parameter LB: Teilstringsuche kann festgelegt werden, welche Datenfelder der Listbox bei einer Teilstringeingabe durchsucht werden.
Warum kann ich im Maskeneditor, obwohl der Customizing-Modus aktiviert ist, keine Felder anklicken?
Es gibt zwei mögliche Ursachen:- Der Datenbereich, in dem die Felder sind,
- wurde noch nicht durch Reinklicken aktiviert (der Datenbereich wird noch grün angezeigt) oder
- ist keine Maske (Layout = 0 oder 1). Der Datenbereich wird grau angezeigt.
- Tipp: Durch Rechte Maustaste in einem Bereich und Auswahl des entsprechenden Eintrags kann das Layout geändert werden.
| Siehe auch: Maskeneditor |
Warum werden alternierende Schattierungen schwarz angezeigt?
Im entsprechenden Datenbereich ist das DI Farbintensität F1 (Farbintensität F2 bzw. Farbintensität F3) zwar gefüllt, das dazugehörige DI Altern. Farbe F1 (Altern. Farbe F2 bzw. Altern. Farbe F3) jedoch nicht. Ist dieses Feld leer, wird standardmäßig die Farbe Schwarz (in der angegebenen Intensität) für die alternierende Schattierung verwendet.- Um dies zu ändern, muss im Modul Datenbereiche in die Modulvariante Layout gewechselt werden und im entsprechenden Datenbereich für das DI Altern. Farbe F1 (Altern. Farbe F2 bzw. Altern. Farbe F3) der gewünschte Wert aus der Listbox ausgewählt werden.
Warum wirkt ein Filterkriterium in rekursiven Strukturen nicht wie erwartet?
Beim Customizen mit rekursiven Strukturen den Parameter Filter anwenden auf prüfen. Dieser steuert, auf welcher Ebene in der rekursiven Struktur die Filterkriterien wirken.Warum wirkt ein Filterkriterium nicht?
Über den Parameter Filter deaktiviert kann ein Filterkriterium deaktiviert werden.Warum werden die Charts in einem kopierten Modul nicht angezeigt?
- Aus welchem Datenbereich die Daten für den Chart kommen, wird im Chart-Datenfeld im Feld Datenfeld-Konfiguration im Parameter
da_id=''definiert.
Beispiel"""Define Chart - Properties""" da_id='045968'
- Wird ein Modul kopiert, ändern sich die IDs der Datenbereiche. Daher muss in Chart-Datenfeldern die Datenbereichs-ID des Quell-Moduls durch die des neuen ersetzt werden.
- Welche Datenbereichs-ID verwendet werden muss, findet man am einfachsten heraus, in dem man sich anschaut, welcher Datenbereich im Quell-Modul verwendet wurde und welcher diesem im kopierten Modul entspricht.
Warum kann in einem Hyperlink-Feld eine aus der Vorlage einkopierte Datei nicht geöffnet werden?
Möglichweise ist der im Customizing hinterlegte Pfad der Vorlage-Datei nicht korrekt. Dieser Pfad wird im Unter-DI mit der Funktion CR hinterlegt.| Siehe auch: Hyperlink-Funktion, Hyperlink-Customizing |
Warum wird nach Ändern einer Variable, diese nicht mehr abgeändert im System angezeigt, nachdem der Client neugestartet wurde?
- Variablen verhalten sich in PLANTA project 39 genauso wie in den vorhergehenden Releases, wie z.B. 3.7 und 3.8.
- Das heißt, sie werden beim Starten der Session in den Hauptspeicher geladen und ihre Werte gelten dann, sofern sie nicht direkt in der Datenbank geändert werden, nur für die laufende Session.
- So wird durch die Erhöhung einer Variablen per Python -Makro auch nur der Wert im Hauptspeicher verändert, nicht der in der Datenbank gespeicherte.
- Nach Beenden der Session und Neustarten verfällt daher der Wert im Hauptspeicher und es wird erneut der Wert aus der Datenbank geholt.
- Gleiches gilt, wenn eine zweite Session parallel geöffnet wird. Auch hier wird der in der Datenbank gespeicherte Wert eingelesen.
Warum kann in einem Hyperlink-Feld eine aus der Vorlage einkopierte Datei nicht geöffnet werden?
Ab S 39.5.1
Dieses Problem tritt in Zusammenhang mit der Fehlermeldung Datei [Pfad-Angabe] kann nicht geöffnet werden. Der Pfad ist ungültig oder die Datei existiert nicht. auf. Diese erscheint, wenn auf einem Hyperlink-Feld versucht wird, eine aus der Vorlage einkopierte Datei zu öffnen, der im Customizing hinterlegte Pfad der Vorlage-Datei jedoch nicht korrekt ist. Dieser Pfad wird im Unter-DI mit der Funktion CR hinterlegt.
| Siehe auch: Hyperlink-Funktion, Hyperlink-Customizing |
Bis S 39.5.1.
Möglichweise ist der im Customizing hinterlegte Pfad der Vorlage-Datei nicht korrekt. Dieser Pfad wird im Unter-DI mit der Funktion CR hinterlegt.
| Siehe auch: Hyperlink-Funktion, Hyperlink-Customizing |
Customizing-Tipps ("Wie?")
Was kann ich tun, um die Performance zu verbessern?
- Sind die meisten Module langsam,
- prüfen, ob die Umgebung den Hardware-Anforderungen (im speziellen: Hauptspeicherdimensionierung, Latenz zwischen Datenbank- und Applikationsserver und Datenbank-Performance (z.B. Indizes)) entspricht.
- Ist ein spezielles Modul langsam,
- die Modulkonstruktion prüfen. Z.B.: sind im Modul nicht benötigte Datenbereiche oder Datenfelder enthalten?
- Generell sollten aus Performance-Gründen in einem Modul nur Customizing-Objekte (d.h. Datenbereiche, Datenfelder) eingebunden werden, die wirklich benötigt werden.
- Die Daten in Datenbereichen mit Nie anzeigen = werden ebenfalls geladen, d.h. es reicht nicht aus, einen nicht-benötigten Datenbereich auf Nie anzeigen = zu setzen.
- Filterkriterien überprüfen (Filtern von, Filtern bis, Regulärer Ausdruck)
- Sind auch Filterkriterien auf reellen und nicht nur auf virtuellen Datenfeldern (Dataitems)?
- Grund: Filterkriterien auf reellen Dataitems werden in der Datenbank und die auf virtuellen Dataitems werden im Hauptspeicher ausgewertet, d.h. wenn in einem Modul nur Filterkriterien auf virtuellen Dataitems gesetzt sind, werden erst alle Daten in den Hauptspeicher geladen, um dann dort auf die Filterkriterien einzuschränken.
- Bei virtuellen Datenfeldern wird der Wert in Filtern von und Filtern bis rot und fett markiert.
- Das gleiche gilt für reguläre Ausdrücke.
- Grund: Filterkriterien auf reellen Dataitems werden in der Datenbank und die auf virtuellen Dataitems werden im Hauptspeicher ausgewertet, d.h. wenn in einem Modul nur Filterkriterien auf virtuellen Dataitems gesetzt sind, werden erst alle Daten in den Hauptspeicher geladen, um dann dort auf die Filterkriterien einzuschränken.
- Die meisten Wertebereiche und Hol-Exits können in einen Python-Wertebereich mit der Funktion
computeSqlValueRange()umgewandelt werden. Felder mit solchen Wertebereichen sind der Datenbank bekannt. Daher wirken Filterkriterien auf diesen Feldern nicht erst im Hauptspeicher, sondern auf der Datenbank.
- Sind auch Filterkriterien auf reellen und nicht nur auf virtuellen Datenfeldern (Dataitems)?
- prüfen, ob in diesem Modul viele Implizite Hol-Exits verwendet werden.
- Implizite Holexits sollten aus Performancegründen nicht in Modulen mit großen Datenmengen verwendet werden.
- prüfen, ob in diesem Modul Wertebereiche verwendet werden, in denen die Python-Methode
DtpRecord.get_children()ohne Angabe einer DI-Liste verwendet wird.
- die Modulkonstruktion prüfen. Z.B.: sind im Modul nicht benötigte Datenbereiche oder Datenfelder enthalten?
- Ist das Laden eines Panels langsam oder stockt das Laden der Reiter bei bestimmten Untermodulen,
- Ist eine bestimmte gecustomizte Funktion langsam,
- überprüfen, ob das Makro dieser Funktion das Nachladen von noch nicht vollständig geladenen Untermodulen im aktuellen Panel auslöst.
- Zudem
- sollten häufige bzw. wiederkehrende Datenbankzugriffe über das Customizing, z.B. durch das Einrichten von Caches vermieden werden.
- sollten in Wertebereichen * nur als Dependency vergeben werden, wenn dies aus fachlichen oder technischen Gründen zwingend notwendig ist. Grund: Wertebereiche mit Dependency * werden bei jeder Aktion im System neu berechnet, d.h. auch wenn man z.B. ein anderes Modul öffnet.
Wie müssen Pfade in der Python-Funktion client_exec() angegeben werden?
Für eine Pfadangabe gibt es mehrere Möglichkeiten. ( Die folgenden Varianten der Pfadangabe werden anhand eines beispielhaften Excel-Exports gezeigt.)
- Variante 1:
ppms.client_exec(""" env = get_Env() mod = env.ActivePanel.ModuleManager.__getitem__('%s') doc = mod.CreateExcelExportDocument(fullExportPath = 'C:\\\\Ordner\\\\Unterordner\\\\dateiname') env.GenerateExcelFile(doc) """ % uid)
- Variante 2:
ppms.client_exec(r""" env = get_Env() mod = env.ActivePanel.ModuleManager.__getitem__('%s') doc = mod.CreateExcelExportDocument(fullExportPath = 'C:\\Ordner\\Unterordner\\dateiname') env.GenerateExcelFile(doc) """ % uid)
- Variante 3:
Hinweiseppms.client_exec(""" import os env = get_Env() mod = env.ActivePanel.ModuleManager.__getitem__('%s') doc = mod.CreateExcelExportDocument(fullExportPath = os.path.normpath('C:/Ordner/Unterordner/dateiname')) env.GenerateExcelFile(doc) """ % uid)
- Die Angabe der Dateiendung ist optional.
- Wird nur der Dateiname ohne Angabe eines Pfades angegeben, wird die Datei in den eigenen Dokumenten (
%USERPROFILE%\My Documents) abgelegt.
| Siehe auch: IronPython Api, Python API, Python-Dokumentation zu \ (Backslashes) |
Wie sind die Währungsformate standardmäßig gecustomized?
Im Standard werden systemweit Währungsformate mit zwei Stellen nach dem Komma verwendet. Wenn man dieses Format für einzelne Module bzw. Datenfelder anpassen möchte, kann das auf Datenfeld-Ebene individuell geändert werden (Feld Format-ID ).Wie wird die Höhe und Breite von Listboxen eingestellt?
- Die Höhe (bzw. Breite) von Listboxen muss nicht manuell eingestellt werden, sondern sie wird anhand der Anzahl der Werte (bzw. Breite der Felder) berechnet.
- Es gibt eine minimale und eine maximale Höhe bzw. Breite.
| Siehe auch: Listbox-Customizing |
Wie können Zeilenumbrüche in einem Datenfeld eingestellt werden?
Über den Parameter Mehrzeilig können sowohl manuelle als auch automatische Zeilenumbrüche eingefügt bzw. angezeigt werden.Wie wird der (im Standard blaue) Rahmen um eine Listbox gecustomized?
Die Farbe für den Rahmen um eine Listbox wird im Modul Weitere Modulparameter im Parameter Background-Symbol hinterlegt. Hinweis- Das Blau im Standard hat die Symbol-ID 001975.
Wie kann der Inhalt der aktuellen @L-Variablen (Listenvariablen) angezeigt werden?
Ein Anwender mit Customizer-Rechten kann durch Klick auf die Schaltfläche Aktuelle @L-Werte anzeigen im Modul Variablen die aktuellen @L-Werte einsehen.Wie kann der Inhalt einer bestimmten Variablen angezeigt werden?
Ein Anwender mit Customizer-Rechten kann im Modul Variablen durch Klick auf die Schaltfläche Variableninhalt anzeigen und durch Eingabe der entsprechenden Variablen ihren Inhalt einsehen.Wie kann die Ausrichtung des Datenfeldinhalts geändert werden?
Durch Setzen des Parameters Ausrichtung auf Datenfeldebene.Wie kann man die Performance beim Customizen der Ressourcenstruktur verbessern?
Wenn die Struktur nicht mit einem Datenbereich aus der DT469 Ressourcenstruktur gecustomized wird, sondern in dem Datenbereich der DT467 in dem Feld Rekursive Relation eine entsprechende Relation gecustomized wird.| Siehe auch: Strukturierung über Rekursive Relation |
Wie kann man ein neu aufgerufenes Untermodul als Reiter hinter dem Hauptmodul customizen?
Der Parameterdock_to_module in der Methode open_module() muss gleich der UID des Moduls, an das das Untermodul angedockt werden soll gesetzt werden.
Beispiel
mod_obj = ppms.get_target_module()
mod_obj.open_module('ID des Moduls',forced_status=2,dock_to_module=mod_obj.get_uid(),dock_style=0,foreground=0,focus=0) - Erklärung:
-
mod_objist das Hauptmodul, an das Untermodul angedockt werden soll.
-
Wie kann ich einen Datensatz aus dem DTP auslesen bzw. aus der Datenbank in den Pool holen?
Dafür wird die Python-Methodesearch_record(dt_num, key_list, di_list, dblookup) verwendet.
Parameter -
dt_num: ID der Datentabelle -
key_list: Liste der Python-IDs der 1:1-Schlüssel der Datentabelle- Bei zusammengesetzten Schlüsseln müssen alle DIs (Reihenfolge wie in der Datentabelle) angegeben werden.
-
di_list: Liste mit den DI-IDs (ohne führende Nullen) die im DTP enthalten sein sollen- Hier müssen alle DIs angegeben werden, auf die in der weiteren Berechnung zugegriffen wird.
-
dblookup: Gibt an, ob der Wert aus der Datenbank gelesen werden soll, falls der Datensatz im Pool nicht existiert.
- Die Liste di_list muss mindestens ein DI enthalten.
- 1:1-Schlüssel und Fremdschlüssel werden automatisch in den DTP geladen, auch wenn sie nicht in der Liste di_list enthalten sind.
- Beispiel 1
pr_id = 4711 rec461=ppms.search_record(461, [pr_id], [1052,1062], True)
- Erklärung
- Die Variable rec461 enthält nun eine DTP-Datensatz mit den folgenden DIs (zusätzlich zu den Primär- und Fremdschlüsseln der DT461)
- 001052 Hauptprojekt-ID
- 001062 Manager
- Beispiel 2
pr_id = 4711 task_id = 2010 res_id = R1 rec466=ppms.search_record(466, [pr_id,task_id,res_id], [1510], True)
- Erklärung
- Die Variable rec466 enthält nun eine DTP-Datensatz mit dem DI 001510 Belastung-Ist (zusätzlich zu den Primär- und Fremdschlüsseln der DT466).
Wie kann man zwei (oder mehr) Datenfelder hinter einem Balken anzeigen?
Um neben einem Balken zwei (oder mehr) sogenannte Balkenhilfsfelder anzuzeigen,- für beide Datenfelder im Parameter Balkenlink (DF-Python-ID) die Python-ID des Balken-Datenfelds eintragen
- im Parameter Andockpunkt die Position des Balkenhilfsfelds definieren z.B. 1 Startpunkt ist Balkenende
- X-Pos des 2. Datenfelds = X-Pos des 1. Datenfelds + DF-Breite des 1. Datenfelds + 1
| Siehe auch: Balkenhilfsfelder customizen |
Wie kann ich ein Datenfeld ohne Überschrift anzeigen lassen?
- Wenn der Datenbereich ein horizontales Layout (Parameter Layout = 0) oder ein vertikales Layout (Layout= 1) hat,
- im Modul Datenbereiche für das Datenfeld, dessen Überschrift nicht angezeigt werden soll, in den Parameter DF-Überschrift ein geschütztes Leerzeichen (Alt+ 0160) eintragen.
- Ist der Datenbereich eine Maske (Layout = 2), so kann man die Überschrift ausblenden
- indem man im Modul den Menüpunkt Customizing-Modus aktiviert, die Überschrift anklickt und auf ENTF drückt oder
- indem man die X/Y-Positionen der Überschrift in der Modulvariante Layout im Modul Datenbereiche entfernt.
Customizen in zwei Sessions
Ab S 39.5.0
Ist in der planta_server.conf der Parameter
DTP_CUSTOMIZING_MODE =1, sieht man Customizing-Änderung nur in der aktuellen Session und in allen danach gestarteten, aber nicht in allen, die bereits offen sind. Der Vorteil dieser Einstellung ist eine bessere Performance ab dem zweiten Aufruf. Ist der Parameter deaktiviert, sieht man eine Änderung auch in allen bereits offenen Sessions nach Neustart des Moduls, allerdings dauert jeder nachfolgende Modulaufruf gleich lang wie der erste.
Begründung: Ist der oben genannte Parameter aktiviert (=1), werden die Daten aus den entsprechenden Datentabellen beim ersten Laden in den DTP Cache geladen und bei jedem weiteren Zugriff werden die Daten nicht aus der Datenbank, sondern aus dem DTP Cache verwendet.
Bis 39.5.0
Ist der Parameter DTP Cache im Modul PLANTA Datentabelle für die Datentabellen DT404, DT405, DT406, DT410, DT411 und DT412 aktiviert, sieht man Customizing-Änderung nur in der aktuellen Session und in allen danach gestarteten, aber nicht in allen, die bereits offen sind. Der Vorteil dieser Einstellung ist eine bessere Performance ab dem zweiten Aufruf. Ist der Parameter deaktiviert, sieht man eine Änderung auch in allen bereits offenen Sessions nach Neustart des Moduls, allerdings dauert jeder nachfolgende Modulaufruf gleich lang wie der erste.
Begründung: Ist der Parameter aktiviert, werden die Daten aus den entsprechenden Datentabellen beim ersten Laden in den DTP Cache geladen und bei jedem weiteren Zugriff werden die Daten nicht aus der Datenbank, sondern aus dem DTP Cache verwendet.
STRG + F3 zum Öffnen des aktuellen Datenbereichs/F9 zum Öffnen des Moduls
Ab DB 39.5.0
Nur Benutzer NEU mit Customizer-Rechte = können
- mit F9 das Customizing des aktuellen Moduls im Modul Module aufrufen
- mit STRG + F3 den Datenbereich, in dem sich der Fokus befindet, im Modul Datenbereiche aufrufen.
- Es ist nicht mehr ausreichend, allein den Zugriff auf Customizer-Menüpunkte zu besitzen um auf die oben genannten Customizing-Module zugreifen zu können.
Bis DB 39.5.0
Benutzer, denen die Customizer-Menüpunkte zugeordnet sind, können
- mit F9 das Customizing des aktuellen Moduls im Modul Module aufrufen
- mit STRG + F3 den Datenbereich, in dem sich der Fokus befindet, im Modul Datenbereiche aufrufen.
Automatisches Anlegen von Inkarnationen
Im Data Dictionary gibt es die Möglichkeit Inkarnationen automatisch anzulegen.| Siehe auch: Inkarnationen |
Round Wertebereiche aus Performancegründen in computeSqlValueRange()-Wertebereiche umwandeln
Ein Round Wertebereich wie z.B. der von DI003394 kann unter Umständen performancekritisch sein. Wir empfehlen daher diesen in einencomputeSqlValueRange() -Wertebereich umzuwandeln.
Beispiel alt
(ROUND(DI001510,2) != 0.00) || (ROUND(DI002669,2) != 0.00) || (ROUND(DI002671,2) != 0.00)
def computeSqlValueRange(dt_name):
val = """case
when nvl(DI001510,0)+nvl(DI002669,0)+nvl(DI002671,0) > 0 then 1
when nvl(DI001510,0)+nvl(DI002669,0)+nvl(DI002671,0) = 0 then 0
end"""
return str(val)Python: Wie füge ich Elemente zu einer Liste hinzu?
- Variante 1
value_list = [["R1"],["R2"],["R3"]]
f_list = []
i = 0
for rec in value_list:
f_list.append(value_list[i][0])
i = i + 1- Variante 1 (Strukturiert)
value_list = [["R1"],["R2"],["R3"]]
f_list = []
for rec in value_list:
f_list.append(value_list[0])- Variante 1 (Einzeiler)
value_list = [["R1"],["R2"],["R3"]] f_list = [rec[0] for rec in value_list]
Wie kann ich die Funktion Terminplan kopieren erweitern?
Dafür muss das Modul Terminplan kopieren angepasst werden. Beispiel: Es sollen zusätzlich die Aufgabennotizen kopiert werden.- Einen Datenbereich aus der DT805 Aufgabennotizen anlegen.
- Tipp: den entsprechenden Datenbereich aus dem Terminplan (im Standard: 0099AN) kopieren.
- Eine DA-Python-ID vergeben (z.B.
open_item_notices_area). - Den Datenbereich in das Modul Terminplan kopieren (0099J9) einbinden.
- Es werden nur Werte von Eingabedatenfeldern (Datenfeldverhalten z.B. i, i2 oder li) kopiert.
Wie kann das Summenzeichen Σ angezeigt werden?
Das Symbol mit "Font" = "Symbol" customizen, auf dem gewünschten Feld bzw. der gewünschten Überschrift hinterlegen und S reinschreiben.Wie kann ich ein individuelles Benutzermenü einbinden?
Das Benutzermenümodul kann kopiert und individuell angepasst werden. Die Kopie des Benutzermenüs kann im Modul Skins im Skin der Benutzer im Feld Benutzermenü hinterlegt werden.Wie kann der Splash Screen ausgetauscht werden?
- Die Datei splash.png unter %client_folder%/Resources/ mit der bereitgestellten Datei ersetzen.
| Siehe auch: Splash Screen |
Wie können Texte in E-Mails, z.B. Signaturen, geändert werden?
Für E-Mails können Texte hinterlegt werden, die beim Anlegen einer E-Mail automatisch eingefügt werden; z.B. für Signaturen. Vorgehensweise- Customizer Modul-Customizer Modul Module aufrufen
- Die Modul-ID 009A3F einfügen
- Den Datenbereich DA041375 Stakeholder aufrufen
- Die Baumstruktur von DI026625 E-Mail aufklappen
- Im Datenfeld Datenfeld-Konfiguration in den Parametern subject_text und body_text können automatisch einzufügende Texte für den Betreff und den E-Mail-Inhalt hinterlegt werden.
Meldungen
Neu ab S 39.5.0
Was bedeutet die Meldung Achtung: Ihre Änderung an einer Customizing-Tabelle erzwingt ein Update der Java-Pojo-Klassen. Bitte informieren Sie die Serverentwicklung!
Diese Meldung kommt, wenn in einer Datentabelle der Schemas Q1B und Q2B ein ein neues reeles DI angelegt wird. Das Anlegen, Ändern und Löschen der Dataitems in den Datentabellen der Schemas Q1B und Q2B dürfen nur von PLANTA durchgeführt werden. Die einzige Ausnahme bildet die Datentabelle DT400, die auch kundenindividuelle DIs enthalten darf.Was bedeutet die Meldung IE: (MV creation/application/saving) "[Modulvarianten-ID]" uses these unsupported DIs:DI[Dataitem-ID]
Wenn man für eine Modulvariante im Modul Optionsmodul für MV einen Parameter ändert, deren Bearbeitung vom Programm nicht unterstützt wird, kommt die oben genannte Meldung. Mehr dazu...Beim Customizen eines Python-Wertebereichs kommt eine Fehlermeldung. Was bedeutet sie?
Generell gibt es beim Customizen von Python-Wertebereichen verschiedene Arten von Fehlermeldungen. Beispiele für Fehlermeldungen- IE: "deps" attribute of computeOutput() function in WB code of DI[Dataitem-ID] must be a tuple. The function won't be available.
- Bedeutung: In der Dependency muss ein Tupel angegeben werden. D.h., soll die Funktion nur eine Dependency haben, gibt man das wie folgt an:
deps= ('DI[Dataitem-ID],). Weitere Informationen zu Dependencies
- Bedeutung: In der Dependency muss ein Tupel angegeben werden. D.h., soll die Funktion nur eine Dependency haben, gibt man das wie folgt an:
- IE: processInput() function must take exactly 2 arguments (DataItem reference and old DI value), but in WB code of DI [Dataitem-ID] it takes 1 argument(s) and thus won't be available.
- Bedeutung: Die Funktion processInput() erfordert zwei Übergabe-Werte (di, oldvalue). Weitere Informationen zu den Python-Wertebereichs-Funktionen
Was bedeutet die Fehlermeldung: Python error in macro [Makro-ID]. Class 'SyntaxError': ("Non-UTF-8 code starting with...)
Diese Fehlermeldung bedeutet, dass im Python-Code des entsprechenden Makros nicht zulässige Zeichen verwendet werden, z.B. Umlaute. Dies gilt nicht nur für Python-Code in Makros, sondern für sämtliche Python-Verwendungsbereiche.- Nicht zulässige Zeichen dürfen auch in Kommentaren des Python-Code nicht verwendet werden.
Warum kommt beim Starten eines Moduls die Meldung Skalenzuordnung nicht möglich: MOD [Modul-ID], DA [Datenbereichs-ID], horizontal bar DF [Datenfeld-ID] (DI [Dataitem-ID])?
Diese Meldung kommt, wenn einem Modul kein Skalenbereich zugeordnet ist oder im Skalenbereich der Parameter DA-Klasse ungleich 1 (Skalenbereich) ist.Abbilden von Funktionen aus Releases 3.8 in PLANTA project
Informationen zum Abbilden von Makrobefehlen/-Funktionen in Python finden Sie hier.Technik
- Technische FAQ
- Woran erkennt man, welche/s Release/Version verwendet wird?
- Was ist zu tun, falls auf dem Server, auf dem der Planta-Server läuft, eine neue Java-Version installiert wird?
- Was bedeuten die Meldungen ... no version information available (required by ./planta_server) beim Starten von PLANTA project?
- Beim Starten erscheint die Fehlermeldung Internal error: The handshake failed due to an unexpected packet format. Was bedeutet das?
- Beim Starten des Dienstes bzw. Programms erscheint die Fehlermeldung Der Dienst "XXX" auf "YYY" konnte nicht gestartet werden. ...
- Beim Starten erscheint die Fehlermeldung Fatal Error: Der Typeninitialisierer... Was bedeutet das?
- Beim Versuch nach Excel zu exportieren, kommt die Fehlermeldung Public member ‘ListObjects’ on type ‘Worksheet’ not found. Woran liegt das?
- Wie kann ich aus einem unverschlüsselten Passwort ein verschlüsseltes Hash-Passwort generieren?
- Wie im- bzw. exportiert man am besten eine Datenbank?
- Warum wird die Anmeldung eines Benutzers verweigert?
- Was bedeutet die Meldung java.lang:OutOfMemoryError: ...?
- Was bedeuten die Meldungen ORA-17410: No more data to read from socket oder ORA-08102: index Key not found?
- Was bedeutet die Meldung "WARN session=global c.m.v.a.ThreadPoolAsynchronousRunner -...?
- Was bedeutet die Meldung "Caused by: com.mchange.v2.resourcepool.TimeoutException:...?
Technische FAQ
Woran erkennt man, welche/s Release/Version verwendet wird?
Prüfen der Server-, Client- und Datenbank-Version. Hierzu- den Client starten und anmelden.
- STRG + B drücken: Das Modul Systeminformation öffnet sich.
- Im Feld Customizing steht die Release-Angabe für Ihre Datenbank in Feldern Client und Server sind die 5-stelligen Changeset-Nummern angegeben. Zu welcher Version diese Changesets gehören, finden Sie in der Release Notes-Tabelle.
Was ist zu tun, falls auf dem Server, auf dem der Planta-Server läuft, eine neue Java-Version installiert wird?
Ab PLANTA Server HF 19 ist hier keine weitere Aktion notwendig, da der Planta-Server mit einer eigens mitgelieferten Version von Zulu-Java läuft, unabhängig von der auf dem Server installierten Version.Bei älteren Planta-Servern (Server HF 18) muss der Planta-Dienst einmalig deinstalliert und danach wieder reinstalliert werden. Dazu bitte über die
Skripte im Verzeichnis <Server-Verzeichnis>/yajsw/bat erst den Dienst stoppen (Achtung: Dies beendet ALLE vorhandenen Sessions!), dann deinstallieren, reinstallieren und zuletzt den Server neu starten.Nur, falls auf ein neues Java-Release gewechselt werden soll (also z.B. zwischen Java 1.7 und 1.8), sollte bei Release HF 18 zudem in der Datei <Planta-Server-Verzeichnis>/launch.bat die Variable JAVA_VERSION entsprechend angepasst werden.
Was bedeuten die Meldungen ... no version information available (required by ./planta_server) beim Starten von PLANTA project?
Wenn sie beim Starten von PLANTA folgende bzw. ähnliche Meldungen bekommen, deutet es darauf hin, dass Sie die von PLANTA gelieferten SAP libs verwenden. Für den Fall, dass die SAP-RFC-Schnittstelle nicht genutzt wird, sind im aktuellen Server-Paket funktionslose Ersatzbibliotheken enthalten, die ggf. installierte Originalbibliotheken maskieren. Sollten Sie keine RFC-Schnittstelle (BAPI) verwenden, ist diese Meldung daher nicht relevant.Beim Verwenden der RFC-Funktionalität (BAPI) lesen Sie bitte die folgenden Hinweise:./planta_server: ./libsapucum.so: no version information available (required by ./planta_server)./planta_server: ./libsapnwrfc.so: no version information available (required by ./planta_server)
Beim Starten erscheint die Fehlermeldung Internal error: The handshake failed due to an unexpected packet format. Was bedeutet das?
Erscheint beim Starten des Clients folgende Fehlermeldung, ist im Client die Verschlüsselung aktiviert (Parameter encrypted = yes), der Server ist jedoch nicht entsprechend konfiguriert. Beispiel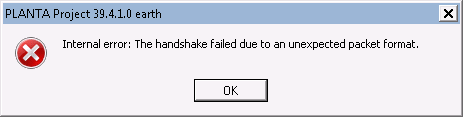
Beim Starten des Dienstes bzw. Programms erscheint die Fehlermeldung Der Dienst "XXX" auf "YYY" konnte nicht gestartet werden. ...
Auf Windows-Servern wird eine aktualisierte Version der Microsoft Visual C++ 2005 SP1 Laufzeitumgebung in der x86-Variante benötigt. Ist diese nicht vorhanden, erscheint die folgende Fehlermeldung:
Beim Starten erscheint die Fehlermeldung Fatal Error: Der Typeninitialisierer... Was bedeutet das?
Erscheint beim Starten des Clients die abgebildete Fehlermeldung, ist .Net 3.5 nicht installiert. Das ist eine Voraussetzung für PLANTA project. Weitere Voraussetzungen Beispiel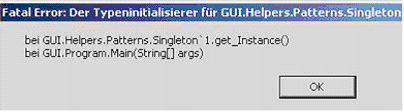
Beim Versuch nach Excel zu exportieren, kommt die Fehlermeldung Public member ‘ListObjects’ on type ‘Worksheet’ not found. Woran liegt das?
Kommt beim Versuch, ein Modul nach Excel zu exportieren, die abgebildete Fehlermeldung, wird die installierte Office-Version nicht unterstützt. Systemvoraussetzungen für PLANTA project finden Sie hier. Beispiel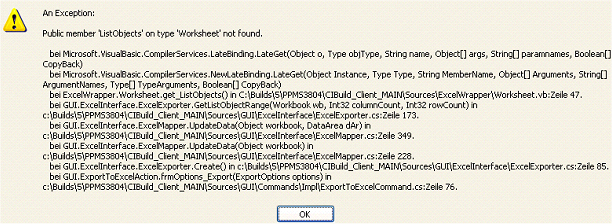
Wie kann ich aus einem unverschlüsselten Passwort ein verschlüsseltes Hash-Passwort generieren?
Informationen hierzu finden Sie hier...Wie im- bzw. exportiert man am besten eine Datenbank?
Für den Im- bzw. Export von Datenbanken werden die Toolsimpdp bzw. expdp verwendet.
| Siehe auch: Im- bzw. Export von Datenbanken |
Neu ab S 39.5.11
Warum wird die Anmeldung eines Benutzers verweigert?
Hierfür gibt es zwei mögliche Gründe: Die absolute oder die benutzerspezifische Grenze für das Anmelden an einem System wurde überschritten. Details- Absolute Grenze: Zur gleichen Zeit können sich nur eine bestimmte Anzahl von Sessions mit dem Server verbinden, die maximale Anzahl kann über den Parameter
parallel_sessionsin derglobals.confeingestellt werden. Wird diese Anzahl überschritten und es wird versucht, einen neuen Client zu starten, erscheint die folgende Meldung und der Client schließt sich wieder: Die neue Session wird verweigert, da die maximale Anzahl an gleichzeitig geöffneten Sessions erreicht wurde. Weitere Informationen dazu finden Sie hier: /twiki/bin/view/Current/TechnischeFAQ#SystemAnmeldung
- Benutzerspezifische Grenze: Für jeden Benutzer kann im Modul Benutzer über den Parameter Parallele Sessions eingestellt werden, an wie vielen Clients sich dieser Benutzer gleichzeitig anmelden kann. Wird diese Anzahl überschritten und es wird versucht, einen neuen Client zu starten, erscheint die folgende Meldung und der Client schließt sich wieder: Die maximal zulässige Anzahl an geöffneten Sessions für diesen Benutzer wurde bereits erreicht. Vor der Neuanmeldung müssen die vorhandenen Clients dieses Benutzers geschlossen werden. Weitere Informationen dazu finden Sie hier: /twiki/bin/view/Current/TechnischeFAQ#SystemAnmeldung
Was bedeutet die Meldung java.lang:OutOfMemoryError: ...?
Die PLANTA-Software hat zu wenig Speicherplatz zur Verfügung. Die Einstellung, wie viel Speicher der PLANTA-Software zur Verfügung steht, kann wie folgt geprüft und ggf. angepasst werden:- In der Konfigurationsdatei
/yajsw/conf/common.confin den folgenden Parametern:-
wrapper.java.initmemory = yy -
wrapper.java.maxmemory = xx
-
- In der Konfigurationsdatei
/config/globals.confin den folgenden Parametern (diese definieren den zur Verfügung stehenden Speicher, sofern sie nicht auskommentiert sind):
#memory limits - activate by uncommenting "memory_limit.max_size"; all sizes are in MiB #mem_limit.max_size = 8192 #mem_limit.session = 512 #mem_limit.calculation = 256 #mem_limit.module = 256 #mem_limit.recalculation = 2048
| Siehe auch: Server Parameter |
Was bedeuten die Meldungen ORA-17410: No more data to read from socket oder ORA-08102: index Key not found?
Diese Fehlermeldungen deuten darauf hin, dass der in den Systemvoraussetzungen angegebene Oracle-Patch 20830993 für die Version 12.1 nicht installiert ist. Falls dies nicht funktionieren sollte, kann auch der Index DT412_DATAITEM_ENABLED in einen NON-UNIQUE-Index geändert werden, um diesen Fehler zu umgehen.Was bedeutet die Meldung "WARN session=global c.m.v.a.ThreadPoolAsynchronousRunner -...?
...com.mchange.v2.async.ThreadPoolAsynchronousRunner$DeadlockDetector@42f4d2d8 -- APPARENT DEADLOCK!!! Creating emergency threads for unassigned pending tasks!"Diese Warnmeldung deutet darauf hin, dass der Aufbau einer Verbindung zur Datenbank zu lange dauert. Dies kann auf Linux-Systemen durch einen leeren entropy pool verursacht werden, was sich durch die Inbetriebnahme von rngd oder das Verlinken von /dev/random auf /dev/urandom beheben lässt.
Was bedeutet die Meldung "Caused by: com.mchange.v2.resourcepool.TimeoutException:...?
...A client timed out while waiting to acquire a resource from com.mchange.v2.resourcepool.BasicResourcePool @77e2a6e2 -- timeout at awaitAvailable()"Ursache siehe in der Beschreibungen der vorhergehenden Meldung.


| I | Attachment | History | Size | Date | Comment |
|---|---|---|---|---|---|
| |
FehlerExcel.png | r1 | 123.6 K | 2011-03-18 - 14:54 | |
| |
Fehlermeldung.png | r1 | 9.0 K | 2011-03-18 - 14:55 |
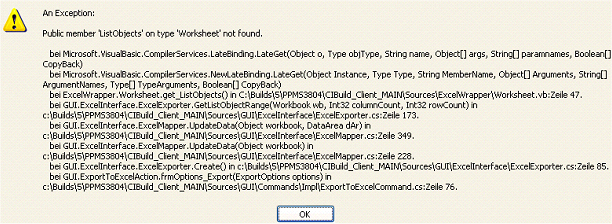{kind=link}
{kind=link}
|